
Comprendre la reconnaissance du locuteur et les attaques vocales contradictoires

Image « haut-parleur » créée par HackerNoon AI Image Generator
Résumé — Les exemples contradictoires audio (AE) ont posé des défis de sécurité importants aux systèmes de reconnaissance de locuteurs du monde réel. La plupart des attaques par boîte noire nécessitent toujours certaines informations du modèle de reconnaissance du locuteur pour être efficaces (par exemple, continuer à sonder et exiger la connaissance des scores de similarité).
Ce travail vise à renforcer le caractère pratique des attaques par boîte noire en minimisant les connaissances de l'attaquant sur un modèle de reconnaissance du locuteur cible.
Bien qu’il ne soit pas possible pour un attaquant de réussir avec une connaissance totalement nulle, nous supposons que l’attaquant ne connaît qu’un court (ou quelques secondes) échantillon de parole d’un locuteur cible.
Sans aucune recherche pour approfondir nos connaissances sur le modèle cible, nous proposons un nouveau mécanisme, appelé entraînement par perroquet, pour générer des AE par rapport au modèle cible. Motivés par les récents progrès en matière de conversion vocale (VC), nous proposons d'utiliser la connaissance d'une phrase courte pour générer des échantillons de parole plus synthétiques qui ressemblent à ceux du locuteur cible, appelés discours de perroquet. Ensuite, nous utilisons ces échantillons de parole de perroquet pour former un modèle de substitution formé par un perroquet (PT) pour l'attaquant.
Dans un cadre commun de transférabilité et de perception, nous étudions différentes manières de générer des AE sur le modèle PT (appelés PT-AE) afin de garantir que les PT-AE peuvent être générés avec une transférabilité élevée vers un modèle cible boîte noire avec une bonne qualité de perception humaine. Des expériences réelles montrent que les PT-AE résultants atteignent des taux de réussite d'attaque de 45,8 % à 80,8 % contre les modèles open source dans le scénario de ligne numérique et de 47,9 % à 58,3 % contre les appareils intelligents, y compris Apple HomePod (Siri). , Amazon Echo et Google Home, dans le scénario en direct[1].
Introduction
Attaques vocales contradictoires contre la reconnaissance vocale [28], [114], [72], [101], [105], [32], [43], [118] et la reconnaissance du locuteur [43], [29], [118 ] sont devenus l'un des domaines de recherche les plus actifs en matière d'apprentissage automatique dans le domaine de la sécurité audio informatique. Ces attaques créent des exemples contradictoires audio (AE) qui peuvent usurper le classificateur de parole dans des paramètres de boîte blanche [28], [114], [72], [52] ou de boîte noire [105], [32], [43]. ], [118], [29], [74], [17]. Comparées aux attaques boîte blanche qui nécessitent la connaissance complète d'un modèle de classification audio cible, les attaques boîte noire ne supposent pas une connaissance complète et ont été étudiées dans la littérature sous différents scénarios d'attaque [29], [118]. Malgré les progrès substantiels réalisés dans la conception des attaques boîte noire, leur lancement peut encore s’avérer difficile dans des scénarios réels dans la mesure où l’attaquant doit toujours obtenir des informations à partir du modèle cible.
Généralement, l'attaquant peut utiliser un processus de requête (ou de sondage) pour connaître progressivement le modèle cible : envoyer de manière répétée un signal vocal au modèle cible, puis mesurer soit le niveau de confiance/le score de prédiction [32], [43], [29] ou les résultats de sortie finaux [118], [113] d'un classificateur. Le processus de sondage nécessite généralement un grand nombre d'interactions (par exemple, plus de 1 000 requêtes [113]), ce qui peut coûter beaucoup de temps et de travail. Cela peut fonctionner dans le domaine numérique, par exemple en interagissant avec des modèles d'apprentissage automatique locaux (par exemple, la boîte à outils Kaldi [93]) ou des plateformes commerciales en ligne (par exemple, Microsoft Azure [12]). Cependant, il peut s'avérer encore plus fastidieux, voire impossible, de sonder des appareils physiques, car les appareils intelligents d'aujourd'hui (par exemple, Amazon Echo [2]) acceptent la parole humaine par voie hertzienne. De plus, certaines connaissances internes du modèle cible doivent encore être supposées connues de l'attaquant (par exemple, l'accès aux scores de similarité du modèle cible [29], [113]). Deux études récentes ont encore limité les connaissances de l'attaquant à (i) [118] ne connaissant que le discours d'une phrase du locuteur cible [118] et nécessitant une enquête pour obtenir les résultats définitifs (accepter ou rejeter) du modèle cible (par exemple, plus de 10 000 fois) et (ii) [30] ne connaissant que le discours d'une phrase pour chaque locuteur inscrit dans le modèle cible.
Dans cet article, nous présentons une nouvelle perspective, encore plus pratique, pour les attaques par boîte noire contre la reconnaissance du locuteur. Notons d’abord que l’hypothèse d’attaque la plus pratique est de ne rien savoir à l’attaquant du modèle cible et de ne jamais sonder le modèle. Cependant, une telle connaissance totalement nulle pour l’attaquant ne conduit probablement pas à des AE audio efficaces. Nous devons assumer certaines connaissances mais les maintenir au niveau minimum pour l'aspect pratique de l'attaque. Notre travail limite les connaissances de l'attaquant à seulement un échantillon de parole d'une phrase (ou quelques secondes) de son locuteur cible sans connaître aucune autre information sur le modèle cible. L’attaquant n’a ni connaissance ni accès aux composants internes du modèle cible. De plus, elle ne sonde pas le classificateur et n'a besoin d'aucune observation des résultats de classification (étiquettes souples ou dures). A notre connaissance, notre hypothèse sur la connaissance de l'attaquant est la plus restreinte par rapport aux travaux antérieurs (notamment avec les deux attaques récentes [118], [30]).
Centré sur cette connaissance d'une phrase du locuteur cible, notre cadre d'attaque de base consiste à (i) proposer une nouvelle procédure d'entraînement, appelée entraînement au perroquet, qui génère un nombre suffisant d'échantillons de parole synthétiques du locuteur cible et les utilise pour construire une modèle formé par perroquet (PT) pour une attaque de transfert supplémentaire, et (ii) évaluer systématiquement la transférabilité et la perception des différents mécanismes de génération d'AE et créer des AE basés sur le modèle PT (PT-AE) vers des taux de réussite d'attaque élevés et une bonne qualité audio.
Notre motivation derrière la formation des perroquets est que les progrès récents dans le domaine de la conversion vocale (VC) ont montré que les méthodes vocales ponctuelles [34], [77], [110], [31] sont capables d'exploiter la parole sémantique humaine. fonctionnalités permettant de générer des échantillons de parole qui ressemblent à la voix d'un locuteur cible dans différents contenus linguistiques. Sur la base de la connaissance d'une phrase de l'attaquant, nous devrions être capables de générer différents échantillons de parole synthétiques de son locuteur cible et de les utiliser pour construire un modèle PT pour la reconnaissance du locuteur. Nos évaluations de faisabilité montrent qu'un modèle PT peut fonctionner de manière similaire à un modèle formé à la vérité terrain (GT) qui utilise les échantillons de parole réels du locuteur cible.
La similitude entre les modèles PT et GT crée une nouvelle question intéressante de transférabilité : si nous créons un PT-AE à partir d'un modèle PT, peut-il fonctionner de la même manière qu'un AE généré à partir du modèle GT (GT-AE) et être transféré vers un modèle noir. -box modèle GT cible ? La transférabilité dans l’apprentissage automatique contradictoire est déjà un concept intrigant. Il a été observé que la transférabilité dépend de nombreux aspects, tels que l'architecture du modèle, les paramètres du modèle, l'ensemble de données d'entraînement et les algorithmes d'attaque [79], [76]. Les évaluations AE existantes se sont principalement concentrées sur les GT-AE sur les modèles GT sans impliquer de données synthétiques. En conséquence, nous menons une étude approfondie sur les PT-AE en termes de génération et de qualité.

Qualité
Nous devons d'abord définir une métrique de qualité pour quantifier si un PT-AE est bon ou non. Il existe deux facteurs importants pour les PT-AE : (i) la transférabilité des PT-AE vers un modèle cible boîte noire. Nous adoptons le taux de correspondance, qui a été étudié de manière approfondie dans le domaine de l'image [79], pour mesurer la transférabilité. Le taux de correspondance est défini comme le pourcentage de PT-AE qui peuvent encore être mal classés comme la même étiquette cible sur un modèle GT à boîte noire. (ii) La qualité de perception des AE audio. Nous menons une étude humaine pour permettre aux participants humains d'évaluer la qualité de la parole des EI avec différents types de porteurs sur une échelle unifiée de score de perception allant de 1 (le pire) à 7 (le meilleur) couramment utilisée dans les études d'évaluation de la parole [47], [ 108], [23], [19], [91], [36], puis construisons des modèles de régression pour prédire les scores humains de qualité de la parole. Cependant, ces deux facteurs sont généralement contradictoires, car un niveau élevé de transférabilité se traduit probablement par une mauvaise qualité de perception. Nous définissons ensuite une nouvelle métrique appelée taux de transférabilité-perception (TPR) pour les PT-AE générés à l'aide d'un type spécifique de transporteurs. Cette métrique est basée sur leur taux de correspondance et leur score de perception moyen, et quantifie le niveau de transférabilité qu'un type de porteur peut atteindre en dégradant un score unitaire de perception humaine. Un TPR élevé peut être interprété comme une transférabilité élevée obtenue grâce à un coût relativement faible de dégradation de la perception.
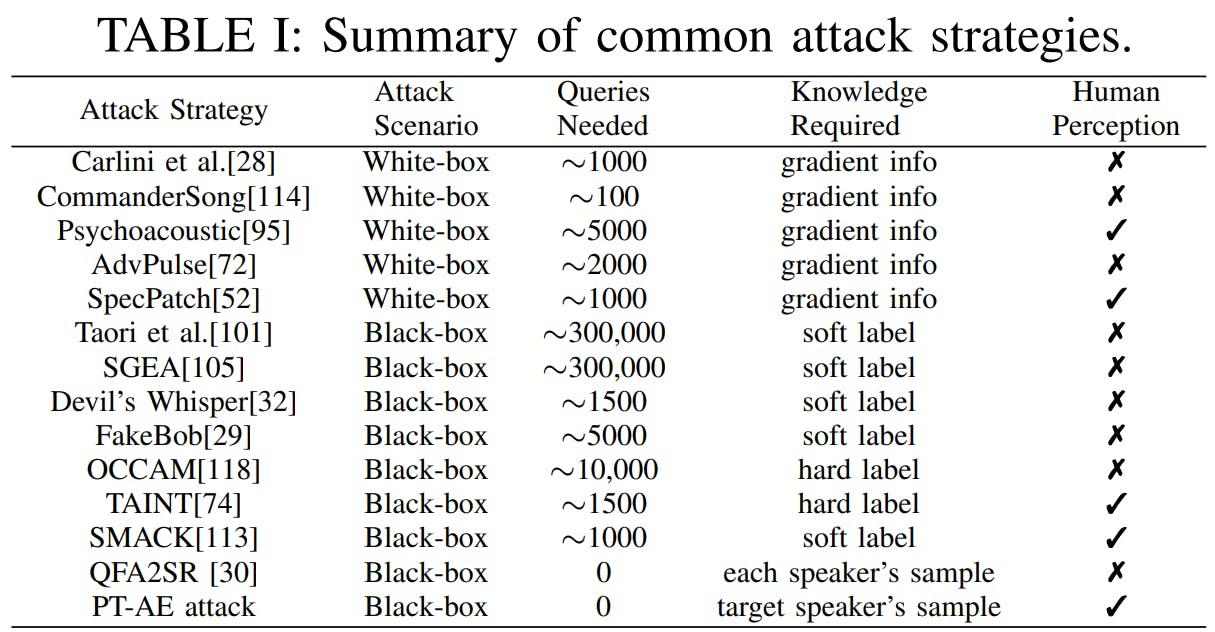
(i) Requêtes : indiquant le nombre typique de sondes nécessaires pour interagir avec le modèle cible de la boîte noire. (ii) Niveau soft : le score de confiance [32] ou le score de prédiction [101], [105], [32], [29], [113] du modèle cible. (iii) Étiquette dure : accepter ou rejeter le résultat [118], [74] du modèle cible. (iv) QFA2SR [30] nécessite l'échantillon de parole de chaque locuteur inscrit dans le modèle cible. (v) La perception humaine signifie intégrer le facteur de perception humaine dans la génération AE.
Dans le cadre du TPR, nous formulons une attaque PTAE en deux étapes qui peut être lancée par voie aérienne contre un modèle de cible de type boîte noire. Dans la première étape, nous passons d'un ensemble complet de porteurs à un sous-ensemble de candidats présentant des TPR élevés pour le locuteur cible de l'attaquant. Dans la deuxième étape, nous adoptons une formulation basée sur l'apprentissage d'ensemble [76] qui sélectionne les meilleurs candidats porteurs de la première étape et manipule leurs caractéristiques auditives pour minimiser un objectif de perte conjoint d'efficacité d'attaque et de perception humaine. Des expériences réelles montrent que l'attaque PT-AE proposée atteint des taux de réussite de 45,8 % à 80,8 % contre les modèles open source dans le scénario de ligne numérique et de 47,9 % à 58,3 % contre les appareils intelligents, y compris Apple HomePod (Siri). Amazon Echo et Google Home, dans le scénario en direct. Par rapport à deux stratégies d'attaque récentes Smack [113] et QFA2SR [30], notre stratégie atteint des améliorations de 263,7 % (succès de l'attaque) et 10,7 % (score de perception humaine) par rapport à Smack, et de 95,9 % (succès de l'attaque) et 44,9 % (score de perception humaine). score de perception) par rapport à QFA2SR. Le tableau I fournit une comparaison des connaissances requises entre l'attaque PT-AE proposée et les stratégies existantes.
Notre contribution majeure peut être résumée comme suit. (i) Nous proposons un nouveau concept de modèle PT et étudions les méthodes VC de pointe pour générer des échantillons de parole de perroquet afin de construire un modèle de substitution pour un attaquant connaissant une seule phrase du locuteur cible. (ii) Nous proposons un nouveau cadre TPR pour évaluer conjointement la transférabilité et la qualité de perception pour les générations PT-AE avec différents types de porteurs. (iii) Nous créons une stratégie d'attaque PT-AE en deux étapes qui s'est avérée plus efficace que les stratégies d'attaque existantes, tout en exigeant le niveau minimum de connaissances de l'attaquant.
II. Contexte et motivation
Dans cette section, nous présentons d’abord le contexte de la reconnaissance du locuteur, puis décrivons les formulations d’attaques contradictoires en boîte noire pour créer des AE audio contre la reconnaissance du locuteur.
A. Reconnaissance du locuteur
La reconnaissance du locuteur devient de plus en plus populaire ces dernières années. Il apporte aux machines la capacité d'identifier un locuteur via ses caractéristiques vocales personnelles, ce qui peut fournir des services personnalisés tels qu'une connexion pratique [4] et une expérience personnalisée [1] pour les appels et la messagerie. Généralement, la tâche de reconnaissance du locuteur comprend trois phases : la formation, l'inscription et la reconnaissance. Il est important de souligner que les tâches de reconnaissance du locuteur [29], [118], [113] peuvent être soit (i) une identification du locuteur (SI) basée sur plusieurs locuteurs, soit (ii) une vérification du locuteur (SV) basée sur un seul locuteur. . Plus précisément, le SI peut être divisé en identification fermée (CSI) et identification ouverte (OSI) [39], [29]. Nous fournissons des informations détaillées à l’annexe A.
B. Attaques contradictoires
Étant donné une fonction de reconnaissance du locuteur f, qui prend une entrée du signal vocal original x et génère une étiquette de locuteur y, un attaquant adverse vise à trouver un petit signal de perturbation δ ∈ Ω pour créer un audio AE x + δ tel que
f(x + δ) = yt, D(x, x + δ) ≤ ϵ, (1)
où yt ̸= y est l'étiquette cible de l'attaquant ; Ω est l'espace de recherche de δ ; D(x, x + δ) est une fonction de distance qui mesure la différence entre la parole originale x et la parole perturbée x+δ et peut être la distance basée sur la norme Lp [29], [118] ou une mesure de la différence des caractéristiques auditives. (par exemple, qDev [44] et NISQA [113]) ; et ϵ limite le changement de x à x + δ.
Une formulation d’attaque courante en boîte blanche [28], [72] pour résoudre (1) peut s’écrire sous la forme
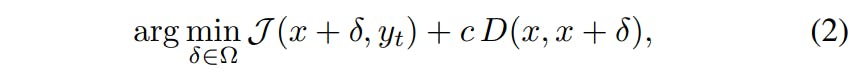
où J (·, ·) est la perte de prédiction dans le classificateur f lors de l'association de l'entrée x + δ à l'étiquette cible yt, qui est supposée connue de l'attaquant ; et c est un facteur permettant d'équilibrer l'efficacité de l'attaque et le changement du discours original.
Une attaque boîte noire n'a aucune connaissance de J (·, ·) dans (2) et doit donc adopter un type de formulation différent en fonction des autres informations qu'elle peut obtenir du classificateur f. Si l’attaque peut sonder le classificateur qui donne un résultat binaire (accepter ou rejeter), l’attaque [118], [74] peut être formulée comme suit :

Puisque (3) contient f(x + δ), l'attaquant doit créer une stratégie de sondage pour générer en continu une version différente de δ et mesurer le résultat de f(x + δ) jusqu'à ce qu'il réussisse. En conséquence, un grand nombre de sondes (par exemple, plus de 10 000 [118]) sont nécessaires, ce qui rend les attaques réelles moins pratiques contre les modèles commerciaux de reconnaissance du locuteur qui acceptent les signaux vocaux par voie hertzienne.

Fig. 1 : La procédure d'attaque par boîte noire basée sur l'entraînement des perroquets.
C. Motivation de conception
Pour surmonter le processus fastidieux de sondage d’une attaque boîte noire, nous visons à trouver un moyen alternatif de créer des attaques pratiques par boîte noire. Étant donné qu’une attaque par boîte noire n’est pas possible sans sonder ou connaître une quelconque connaissance d’un classificateur, nous adoptons l’hypothèse de connaissance préalable utilisée dans [118] selon laquelle l’attaquant possède un très court échantillon audio du locuteur cible (notez que [118] doit sonder le modèle cible en plus de cette connaissance). Cette hypothèse est plus pratique que de laisser l'attaquant connaître les composants internes du classificateur. Compte tenu de ces connaissances limitées, nous visons à supprimer le processus de sondage et à créer des AE efficaces.

Les études existantes se sont concentrées sur un large éventail d’aspects concernant les AE formés à la vérité terrain (GT-AE). Les concepts de discours des perroquets et d'entraînement des perroquets créent un nouveau type d'AE, les AE entraînés par des perroquets (PT-AE), et soulèvent également trois questions majeures sur la faisabilité et l'efficacité des PT-AE dans le cadre d'une attaque pratique par boîte noire : (i ) Un modèle PT peut-il se rapprocher d'un modèle GT ? (ii) Les PT-AE construits sur un modèle PT sont-ils aussi transférables que les GT-AE par rapport à un modèle GT à boîte noire ? (iii) Comment optimiser la génération de PT-AE pour une attaque boîte noire efficace ? La figure 1 montre la procédure globale permettant de répondre à ces questions en vue d'une nouvelle attaque de boîte noire, pratique et sans sonde : (1) nous proposons une méthode de conversion unique en deux étapes pour créer la parole de perroquet pour l'entraînement des perroquets dans la section III ; (2) nous étudions différents types de générations PT-AE à partir d'un modèle PT concernant leur transférabilité et leur qualité de perception dans la section IV ; et (3) nous formulons une attaque boîte noire optimisée basée sur les PT-AE dans la section V. Ensuite, nous effectuons des évaluations complètes pour comprendre l'impact de l'attaque proposée sur les systèmes audio commerciaux dans la section VI.
D. Modèle de menace
Dans cet article, nous considérons un attaquant qui tente de créer un AE audio pour tromper un modèle de reconnaissance du locuteur de telle sorte que le modèle reconnaisse l'AE comme la voix d'un locuteur cible. Nous adoptons une attaque boîte noire en supposant que l'attaquant n'a aucune connaissance de l'architecture, des paramètres et des données de formation utilisés dans le modèle de reconnaissance vocale. Nous supposons que l'attaquant dispose d'un échantillon de parole très court (quelques secondes dans nos évaluations) du locuteur cible, qui peut être collecté dans des lieux publics [118], mais l'échantillon n'est pas nécessairement utilisé pour l'entraînement au modèle cible. Nous nous concentrons sur un scénario plus réaliste dans lequel l’attaquant ne sonde pas le modèle, ce qui est différent de la plupart des études d’attaques par boîte noire [113], [29], [118] qui nécessitent de nombreuses sondes. Nous supposons que l'attaquant doit lancer l'injection sans fil contre le modèle (par exemple, Amazon Echo, Apple HomePod et Google Assistant).
III. Formation des perroquets : Faisabilité et évaluation
Dans cette section, nous étudions la faisabilité de créer un discours de perroquet pour le dressage des perroquets. Comme la parole du perroquet est la parole oneshot synthétisée par une méthode VC, nous introduisons d'abord l'état de l'art de la VC, puis proposons une méthode en deux étapes pour générer la parole du perroquet, et enfin évaluons comment un modèle PT peut se rapprocher d'un discours de perroquet. Modèle GT.
A. Conversion vocale en une seule fois
Synthèse de données : la génération de données avec certaines propriétés est couramment utilisée dans le domaine de l'image, notamment la transformation des données existantes via l'augmentation des données [92], [98], [80], [98], la génération de données de formation similaires via des réseaux contradictoires génératifs (GAN). ) [50], [35], [18], et générer de nouvelles variations des données existantes par des auto-encodeurs variationnels (VAE) [62], [48], [53], [24]. Ces approches peuvent également être trouvées dans le domaine audio, comme l'augmentation de la parole [63], [90], [64], [69], la synthèse vocale basée sur GAN [33], [65], [59], [21 ] et la synthèse vocale basée sur la VAE [62], [55], [117]. Plus précisément, VC [94], [75], [70], [104], [31] est une approche spécifique de synthèse de données qui peut utiliser la parole d'un locuteur source pour générer davantage d'échantillons vocaux qui ressemblent à ceux d'un locuteur cible. Des études récentes [107], [40] ont révélé qu'il peut être difficile pour les humains de distinguer si la parole générée par une méthode VC est réelle ou fausse.
Conversion vocale en une seule fois : VC récent a été développé en utilisant uniquement la parole en une seule fois [34], [77], [110], [31] (c'est-à-dire les méthodes ne connaissant qu'une seule phrase prononcée par le locuteur cible) pour convertir la voix du locuteur source à celle du locuteur cible. Cette hypothèse de connaissances limitées correspond bien au scénario de boîte noire considéré dans cet article et nous motive à utiliser des données vocales ponctuelles pour former un modèle local pour l'attaquant boîte noire. Comme le montre le côté gauche de la figure 1, un modèle VC prend les échantillons de parole du locuteur source et du locuteur cible comme deux entrées et produit un échantillon de parole de perroquet comme sortie. L'attaquant peut associer le seul échantillon de parole, obtenu du locuteur cible, avec différents échantillons de parole provenant d'ensembles de données de parole publique en tant que différentes paires d'entrées du modèle VC pour générer différents échantillons de parole de perroquet, qui devraient ressembler à la voix du locuteur cible. construire une formation de perroquet.
B. Génération et performances d'échantillons vocaux Parrot
Nous proposons d'abord notre méthode pour générer des échantillons de parole de perroquet, puis nous les utilisons pour construire et évaluer un modèle PT. Pour générer la parole de perroquet, nous proposons deux composants de conception, motivés par des résultats existants basés sur des méthodes VC one-shot [60], [61], [40].
Sélection initiale de l'enceinte source.
Les études existantes sur la CV [60], [61] ont montré que la CV intra-genre (par exemple, de femme à femme) semble avoir de meilleures performances que la CV intergenre (par exemple, de femme à homme). Comme une différence majeure entre les voix masculines et féminines réside dans la fonction de hauteur [70], [104], [75], qui représente les informations de fréquence de base d'un signal audio, notre intuition est que la sélection d'un locuteur source dont la voix a la fonction de hauteur similaire au haut-parleur cible peut améliorer les performances du VC. Par conséquent, pour qu'un attaquant connaissant un court échantillon de parole du locuteur cible puisse générer davantage d'échantillons de parole de perroquet, la première étape de notre conception consiste à trouver le meilleur locuteur source dans un ensemble de données vocales (qui peut être un ensemble de données public ou celui de l'attaquant). ensemble de données) de telle sorte que le haut-parleur source ait la distance de hauteur moyenne minimale par rapport au haut-parleur cible.
Conversions itératives.
Après avoir sélectionné le locuteur source initial, nous pouvons adopter une méthode VC unique existante pour produire un échantillon de parole à partir d’une paire d’échantillons du locuteur source initial et du locuteur cible. Comme l'échantillon de sortie, dans le cadre du mécanisme VC, est censé présenter les caractéristiques audio du locuteur cible mieux que le locuteur source initial, nous utilisons cette sortie comme entrée de l'échantillon d'un nouveau locuteur source et exécutons à nouveau la méthode VC pour obtenir la deuxième sortie. échantillon. Nous exécutons ce processus de manière itérative pour finalement obtenir un échantillon de parole de perroquet. Les conversions itératives de VC ont été étudiées dans une récente étude médico-légale audio [40], qui a révélé que le changement des locuteurs cibles lors des conversions itératives peut aider le locuteur source à masquer ses empreintes vocales, c'est-à-dire à obtenir plus de fonctionnalités d'autres locuteurs pour créer des caractéristiques vocales. du haut-parleur source d’origine moins évident. Par rapport à cette méthode de masquage de fonctionnalités, nos conversions itératives peuvent être considérées comme un moyen d'amplifier les caractéristiques audio du même locuteur cible pour générer une parole de perroquet.
Nous avons mis en place la sélection du locuteur source et les conversions itératives avec des modèles VC uniques pour générer et évaluer les performances des échantillons de parole de perroquet sur la figure 2.
Configuration expérimentale : il existe une large gamme de solutions one-shot

Fig. 2 : Génération vocale Parrot : configurations et évaluations.

Fig. 3 : FPR sous différentes sources initiales de locuteur

Fig. 4 : FPR sous différents nombres d'itérations.
Méthodes VC récemment disponibles pour la génération de parole de perroquet. Nous considérons et comparons les performances d'AutoVC [9], BNE [13], VQMIVC [15], FreeVC-s [10] et AGAIN-VC [7]. Comme le montre la figure 2, nous utilisons l'ensemble de données VCTK [103] pour entraîner chaque modèle VC. L'ensemble de données comprend 109 anglophones avec environ 20 minutes de discours. Nous sélectionnons également les locuteurs sources à partir de cet ensemble de données. Nous sélectionnons 6 locuteurs cibles dans l'ensemble de données LibriSpeech [87], qui est différent de l'ensemble de données VCTK, de sorte que la formation VC n'a aucune connaissance préalable du locuteur cible. Un seul court échantillon (environ 4 secondes avec 10 mots anglais) d'un locuteur cible est fourni à chaque modèle VC pour générer différents échantillons de parole de perroquet. Nous construisons un réseau neuronal à retard (TDNN) comme modèle GT pour une tâche CSI visant à évaluer comment les échantillons de perroquets peuvent être classés avec précision comme la voix du locuteur cible. Le modèle GT est formé avec 24 locuteurs (12 hommes et 12 femmes) de LibriSpeech (y compris les 6 locuteurs cibles et 18 locuteurs sélectionnés au hasard). Le modèle entraîne 120 échantillons de parole (4 à 15 secondes) pour chaque locuteur et donne une précision de test de 99,3 %.
Métriques d'évaluation
Nous utilisons le taux de faux positifs (FPR) [56], [29] pour évaluer l'efficacité de la parole du perroquet, c'est-à-dire le pourcentage d'échantillons de parole de perroquet classés par le classificateur TDNN comme voix du locuteur cible. Plus précisément, FPR = FP/(FP + TN), où les faux positifs (FP) indiquent le nombre de cas dans lesquels le classificateur identifie à tort des échantillons de parole de perroquet comme l'étiquette du locuteur cible ; Les vrais négatifs (TN) représentent le nombre de cas dans lesquels le classificateur rejette correctement les échantillons de parole de perroquet comme toute autre étiquette, à l'exception du locuteur cible.
Résultats de l'évaluation
Nous évaluons d’abord l’impact de la sélection initiale du locuteur source sur différents modèles de VC. Nous définissons le nombre de conversions itératives sur un et l'échantillon de parole du locuteur cible est d'environ 4,0 secondes (10 mots anglais), ce qui est le même pour tous les modèles VC. Nous utilisons la distance de hauteur entre les enceintes source et cible comme norme d'évaluation. Plus précisément, nous trions d'abord les 110 enceintes sources de l'ensemble de données VCTK en fonction de leurs distances moyennes de hauteur par rapport à l'enceinte cible. Nous utilisons minimum, médiane et maximum pour désigner les enceintes sources qui ont respectivement les distances de hauteur la plus petite, médiane et la plus grande parmi toutes les enceintes sources. Nous utilisons chaque méthode VC pour générer 12 échantillons de parole de perroquet différents pour chaque locuteur cible (soit un total de 72 échantillons pour 6 locuteurs cibles sous chaque méthode VC). La figure 3 montre que la distance de hauteur du haut-parleur source peut affecter considérablement le FPR. Pour le modèle VC le plus efficace, Free-VCs, nous pouvons observer que le FPR peut atteindre 0,7222 lorsque le locuteur source est choisi pour avoir la distance minimale par rapport au locuteur cible, indiquant que 72,22 % des échantillons de parole de perroquet peuvent tromper le modèle GT TDNN dans Fig. 2. Même pour le modèle AGAIN-VC le moins performant, nous pouvons toujours observer que le FPR de distance minimale (0,1944) est près de 3 fois le FPR de distance maximale (0,0694). En conséquence, le haut-parleur source avec la distance de hauteur la plus faible est plus efficace pour améliorer les performances du VC (c'est-à-dire conduisant à un FPR plus élevé).
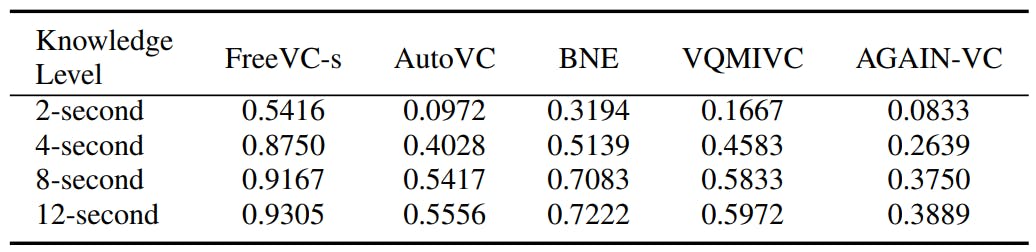
TABLE II: VC Performance under different knowledge levels.
Ensuite, nous évaluons l'impact des conversions itératives sur le FPR. La figure 4 montre les FPR avec différents nombres d'itérations pour chaque modèle VC (avec une itération nulle signifiant aucune conversion et utilisant directement le TDNN pour classer la parole de chaque locuteur source). Il ressort de la figure qu'avec l'augmentation du nombre d'itérations, le FPR gagne initialement puis reste dans une plage relativement stable. Par exemple, le FPR des FreeVC-s atteint la valeur la plus élevée de 0,9305 après 5 itérations, puis chute légèrement à 0,9167 après 7 itérations. Sur la base des résultats de la figure 4, nous avons défini 5 itérations pour la génération de parole de perroquet.
Nous nous intéressons également au degré de connaissance du locuteur cible nécessaire pour que chaque modèle VC génère un discours de perroquet efficace. Nous définissons le niveau de connaissances en fonction de la longueur du discours de l’orateur cible prononcé devant le VC. Plus précisément, nous recadrons le discours du locuteur cible en quatre niveaux : i) niveau de 2 secondes (environ 5 mots), ii) niveau de 4 secondes (10 mots), iii) niveau de 8 secondes (15 mots) et iv) Niveau 12 secondes : (22 mots). Pour chaque modèle VC, nous générons 288 échantillons de parole de perroquet (12 pour chaque locuteur cible avec chaque niveau de connaissances différent) pour interagir avec le modèle GT. Tous les échantillons sont générés en choisissant le haut-parleur source initial avec la distance de hauteur minimale et en définissant le nombre d'itérations sur 5.
Le tableau II évalue les FPR selon différents niveaux de connaissances du locuteur cible. On peut constater que la longueur du discours du locuteur cible affecte considérablement l’efficacité des échantillons de discours du perroquet. Par exemple, AutoVC atteint les FPR de 0,0972 et 0,5417 avec des échantillons de parole de 2 et 4 secondes du locuteur cible, et augmente finalement jusqu'à 0,5556 avec la connaissance de 12 secondes. On observe également que FreeVCs fonctionne le mieux dans toutes les méthodes VC pour chaque niveau de connaissances (par exemple, 0,9167 pour le niveau de connaissances de 8 secondes). Nous pouvons également constater que l’augmentation du FPR devient légère entre 8 secondes et 12 secondes de connaissance vocale. Par exemple, FreeVCs passe de 0,9167 (8 secondes) à 0,9305 (12 secondes) et VQMIVC passe de 0,5833 (8 secondes) à 0,5972 (12 secondes). Dans l'ensemble, les résultats du tableau II révèlent que même sur la base d'une quantité très limitée (c'est-à-dire quelques secondes) de la parole du locuteur cible, des échantillons de parole de perroquet peuvent toujours être générés efficacement pour imiter les caractéristiques vocales du locuteur et tromper un classificateur de locuteur. dans une large mesure.
C. Formation de perroquet comparée à la formation de vérité sur le terrain
Nous avons montré que les échantillons de parole de perroquet peuvent être efficaces pour induire en erreur un modèle de classification de locuteurs formés au GT. De plus, nous utilisons des expériences pour évaluer plus en détail comment un modèle PT entraîné par des échantillons de parole de perroquet est comparé à un modèle GT. Nous comparons les performances de classification des modèles PT et GT. D'après nos résultats, les modèles PT présentent des performances de classification comparables et pouvant s'approcher des modèles GT. Nous incluons les configurations expérimentales et les résultats dans l'annexe B.
IV. GénérationPT-AE : Une perspective conjointe de tranférabilité et de perception
Dans cette section, nous visons à évaluer si les PT-AE sont aussi efficaces que les GT-AE par rapport à un modèle GT à boîte noire. Nous résumons d'abord les méthodes de génération AE qui utilisent différents types de formes d'onde audio (c'est-à-dire les porteuses). Ensuite, nous quantifions la qualité perceptuelle humaine des AE avec différents porteurs, puis utilisons le taux de correspondance pour mesurer la transférabilité des PT-AE aux modèles GT. Enfin, nous définissons la métrique unifiée, le rapport transférabilité-perception (TPR), pour évaluer les PT-AE.
A. Porteuses dans la génération audio AE
Des études récentes sur les attaques audio ont pris en compte différents vecteurs de perturbation audio pour générer des AE via des algorithmes de génération spécifiques. Nous résumons trois principaux types de transporteurs.
Porteurs de bruit : les méthodes traditionnelles [29], [74] adoptent généralement une méthode d'estimation de gradient pour générer des AE audio dans l'espace Lp non restreint avec le signal de perturbation initial défini généralement comme un bruit gaussien. Ceci conduit à un son bruyant malgré certaines méthodes psychoacoustiques [95], [52], [74] qui peuvent être utilisées pour atténuer l’effet bruyant.
Porteuses aux caractéristiques tordues : la manipulation directe de la caractéristique auditive d'un signal vocal pourrait rendre un classificateur sensible mais furtif pour les oreilles humaines. Des travaux existants [17], [113] ont montré que modifier les phonèmes ou changer la prosodie de la parole peut également usurper le classificateur audio tout en préservant la qualité de perception.
Porteurs de sons environnementaux : l'attaque de la phase d'inscription [39] a utilisé des sons environnementaux (par exemple, la circulation) pour créer le signal de perturbation afin d'empoisonner un modèle de reconnaissance du locuteur.
B. Quantification de la qualité perceptuelle des EI de la parole
Nous devons d’abord trouver une métrique de perception appropriée pour mesurer avec précision la qualité perceptuelle humaine des EI en fonction de différents porteurs. Des études récentes [44], [113] ont souligné que les mesures traditionnelles, telles que le rapport signal sur bruit (SNR) [32] et la norme Lp [114], [29], [118], ne peuvent pas refléter directement le perception humaine. Ils ont utilisé différentes mesures basées sur des études humaines pour mesurer la qualité perceptuelle des AE avec certains types de porteurs (c'est-à-dire qDev pour les AE musicaux dans [44] et NISQA pour les AE aux fonctionnalités déformées [113]). De plus, nous remarquons également que le rapport harmoniques sur bruit (HNR) [115] est une métrique courante adoptée en science de la parole pour mesurer la qualité d'un signal vocal. Compte tenu de ces mesures de perception potentielles, nous visons à mener une étude humaine pour découvrir la meilleure mesure pour mesurer la qualité perceptuelle sur une diversité de porteurs d'AE qui nous intéressent.
Génération d'ensembles de données pour l'étude humaine : nous créons l'ensemble de données d'étude humaine avec des porteurs de bruit [28], [95], [52], [29], [118], [74], des porteurs à caractéristiques tordues [113] et des porteurs environnementaux. [39]. Nous choisissons 30 signaux vocaux originaux (d'une durée de 5 à 15 secondes) dans l'ensemble de données vocales existant [82]. Nous modifions ces signaux originaux en ajoutant différents types de porteuses pour former des signaux vocaux perturbés pour l'étude humaine. Nous utilisons le rapport signal sur porteuse (SCR) pour contrôler l'énergie d'une porteuse de perturbation ajoutée à un signal original. Par exemple, un SCR de 0 dB signifie que la porteuse et le signal d'origine ont le même niveau d'énergie. Nous considérons que les porteuses suivantes doivent être ajoutées aux signaux originaux.
- Porteuses de bruit : l'ensemble de données [82] fournit une large gamme de signaux vocaux bruités. Le bruit est distribué de manière gaussienne et peut être généré avec différents SNR. Nous avons généré 30 échantillons de parole dont les SNR sont uniformément répartis entre 0 et 30 dB. A noter que la métrique SCR est équivalente à la métrique du SNR dans le cas des porteurs de bruit.
- Porteuses à caractéristiques tordues : pour les signaux vocaux à caractéristiques tordues, nous décalons la tonalité (c'est-à-dire la hauteur) [113] pour générer des porteuses à tonalité torsadée. Plus précisément, nous décalons vers le haut/bas de 25 demi-tons[2] le discours original pour créer les porteuses tordues, et ajoutons ces porteuses au discours original avec différents niveaux SCR. Pour modifier le rythme, nous accélérons et ralentissons la parole allant de 0,5 à 2 fois son débit de parole.
- Porteurs de bruits environnementaux : les porteurs de bruits environnementaux sont sélectionnés à partir des ensembles de données à grande échelle sur les bruits environnementaux étiquetés par l'homme [47] avec des catégories comprenant les sons naturels (par exemple, le vent et les vagues), les bruits de choses (par exemple, les véhicules et les moteurs), les sons humains (par exemple, les sifflements), les sons d'animaux (par exemple, les animaux de compagnie) et la musique (par exemple, les instruments de musique). Pour chaque catégorie, nous avons sélectionné au hasard 6 clips audio.
Nous avons créé un total de 90 échantillons de parole perturbés, 30 échantillons pour chaque porteuse définie à différents niveaux SCR.
Implication des participants humains : Nous avons recruté 30 volontaires, qui sont des étudiants sans problèmes d'audition (autodéclarés). Notre procédure d'étude a été approuvée par notre comité d'examen institutionnel (IRB). Il est demandé à chaque volontaire d'évaluer la similarité entre une paire d'extraits vocaux originaux et perturbés par le porteur en utilisant une échelle de 1 à 7 communément adoptée dans les études d'évaluation de la parole [47], [108], [23], [19], [91], [36], où 1 indique le moins de similitude (c'est-à-dire que les haut-parleurs sonnent très différemment entre les deux clips) et 7 représente le plus de similitude (c'est-à-dire que les haut-parleurs sonnent très similaires).
Qualité perceptuelle de différents porteurs : la figure 5 compare les scores humains moyens à différents niveaux de SCR pour différents porteurs. Nous pouvons clairement voir que la qualité de perception des porteurs de bruit s'améliore progressivement avec l'augmentation du SCR, ce qui indique que moins le porteur de bruit est intense, meilleure est la perception de la parole perturbée. Il est intéressant de noter que les scores humains des porteurs de sons environnementaux et aux caractéristiques tordues ne sont pas étroitement corrélés au SCR. Les deux peuvent en effet obtenir de meilleurs scores humains à des niveaux SCR inférieurs (par exemple, 10-15 dB contre 15-20 dB). La figure 5 montre également que, dans l'ensemble, les porteurs de bruit environnemental donnent de meilleurs scores humains que les porteurs de caractéristiques tordues et les porteurs de bruit.

Fig. 5 : scores humains pour les signaux vocaux perturbés par la porteuse.

TABLEAU III : Évaluation de différentes métriques.


C. Mesurer la transférabilité des PT-AE
Nous passons ensuite à l'évaluation de la transférabilité de différents transporteurs pour les AE basés sur le PT.
1) Création de modèles cibles et de substitution : la première étape de l'évaluation de la transférabilité consiste à construire i) des modèles cibles, qui font référence aux modèles que l'attaquant doit attaquer à l'aide de PTAE, et ii) des modèles de substitution, qui sont utilisés par l'attaquant pour générer des PT-AE par rapport aux modèles cibles. On sait que la différence entre les modèles cible et substitut peut affecter la transférabilité des EI (76).
Construire des modèles cibles : Nous envisageons de construire une diversité de modèles cibles avec 4 modèles de reconnaissance du locuteur basés sur DNN, dont 2 modèles CNN [58] et 2 modèles TDNN [99], [100]. Ces 4 modèles cibles sont entraînés avec les mêmes 6 locuteurs cibles (3 mâles et 3 femelles). Nous les sélectionnons au hasard dans LibriSpeech et utilisons 120 échantillons de parole pour chaque locuteur pour la formation. Comme les 4 modèles cibles ont des architectures et des paramètres variables (c'est-à-dire le nombre de couches et les poids), nous les désignons par CNN-A, CNN-B, TDNN-A et TDNN-B. Leurs précisions sont respectivement de 100,0 %, 96,5 %, 99,3 % et 97,2 %.


2) Générations d'AE via différents porteurs : Après avoir construit les modèles de substitution et cibles, nous générons des AE à partir des modèles de substitution en utilisant les trois types de porteurs sur la base des études existantes.
- Pour le porteur de bruit, nous résolvons le problème de la boîte blanche (2) via la descente de gradient projetée (PGD) [49], et nous choisissons la norme L∞ comme métrique de distance, ce qui montre de bonnes performances dans le tableau III. Nous fixons ϵ = 0,05 pour contrôler la norme L∞.
- Pour la porteuse tordue, nous tordons la hauteur et le rythme de la parole originale [113], [44] en utilisant la métrique de perception SRS comme mesure de distance. Comme le SRS basé sur une forêt aléatoire n'est pas différentiable, nous utilisons la recherche de grille pour résoudre 2. Plus précisément, nous décalons vers le haut/bas de 25 demi-tons de hauteur, et le pas de changement de hauteur minimal ∆p = 1 demi-ton. Nous accélérons et ralentissons la parole dans une plage de 0,2 à 2,0 de son débit de parole, le pas minimal de changement de rythme ∆r étant de 0,2.
- Pour le support sonore environnemental, nous choisissons 30 sons environnementaux parmi [47] qui comprennent les sons naturels, les sons de choses, les sons humains, les sons d'animaux et la musique. Sur la base du SRS pour représenter la distance D dans (2), nous résolvons (2) en trouvant les meilleurs poids linéaires [44] de différents sons environnementaux en utilisant une recherche par grille avec le pas de recherche minimal étant de 0,1ϵ avec un seuil ϵ fixé à 0,05 (identique au seuil du porteur de bruit).
Pour chaque type de transporteur, nous générons 20 PT-AE à partir de chaque modèle de substitution PT (un total de 480 PT-AE). De plus, nous générons 20 GT-AE à partir de chaque modèle de substitution GT à des fins de comparaison (également un total de 480 GT-AE).
3) Métrique d'évaluation de la transférabilité : La transférabilité a été largement étudiée dans le domaine de l'image [88], [76], [89], [79]. Une mesure d'évaluation importante dans les attaques de transfert [79], [76] est le taux de correspondance, qui mesure le pourcentage d'AE qui peuvent faire prédire à la fois un modèle de substitution et un modèle cible la même étiquette erronée. Nous utilisons la métrique du taux de correspondance pour mesurer la transférabilité des PT-AE dans ce travail. Plus précisément, nous pouvons tester un PT-AE généré : x+δ avec à la fois le modèle de substitution f(·) et le modèle cible f ′ (·). Si f(x +δ)=f ′ (x+δ) ̸= f(x), nous pouvons dire que x+δ est un AE apparié pour f(·) et f ′ (·). Le taux de correspondance est le rapport entre le nombre d’AE appariés et le nombre total d’AE.

Le tableau IV montre les taux de correspondance entre les différents modèles de substitution et cibles pour les 3 types de porteurs AE. Nous pouvons voir que le support environnemental sain atteint une meilleure transférabilité AE que les supports de bruit et de caractéristiques tordues en termes de taux de correspondance moyen sur les 4 modèles cibles. En particulier, les PT-AE basés sur les sons environnementaux ont des taux de correspondance de 0,23 à 0,27, contre 0,10 à 0,14 (porteuse de bruit) et 0,15 à 0,22 (porteuse à caractéristiques tordues). Les résultats démontrent que l’utilisation des sons environnementaux comme vecteurs permet d’obtenir la meilleure transférabilité des PT-AE d’un modèle de substitution PT à un modèle cible.
Le tableau IV compare également les taux de correspondance des PT-AE générés à partir des modèles PT par rapport aux GT-AE générés à partir des modèles GT. Nous pouvons observer que le taux d’appariement des PTAE est légèrement inférieur à celui de leurs homologues GT. Par exemple, en utilisant la porteuse de bruit, les GT-AE basés sur GT-TDNN-D atteignent le meilleur taux de correspondance moyen de 0,1625 ; en revanche, les PT-AE basés sur PT-TDNN-D obtiennent un taux de correspondance moyen légèrement inférieur de 0,1375. Dans l’ensemble, nous pouvons constater que les PT-AE sont légèrement moins transférables que les GT-AE, mais restent efficaces contre les modèles cibles, notamment en utilisant le support environnemental.
D. Définir le rapport transférabilité-perception pour l’évaluation
Maintenant, étant donné une porteuse AE de type C ∈ {bruit, caractéristiques tordues, sons environnementaux}, nous disposons des métriques de SRS(C) et du taux de correspondance m(C) pour mesurer la qualité perceptuelle et la transférabilité des PT-AE de type C. , respectivement. Nous définissons une métrique commune, nommée Transférabilité-Perception Ratio (TPR), comme
TPR(C) = m(C)/(8 − SRS(C)), (4)
où 8 - SRS (C) va de 1 à 7, indiquant la perte de score vers la meilleure qualité de perception humaine. La valeur résultante de TPR(C) est comprise entre [0, 1] et quantifie, en moyenne, le degré de transférabilité (en termes de taux de correspondance) que nous pouvons obtenir en dégradant une unité de qualité perceptuelle humaine (en termes de SRS). . Un TPR plus élevé indique une meilleure qualité de l’AE d’un point de vue conjoint de transférabilité et de perception.
Comme l'attaquant ne connaît qu'une seule phrase du discours de son locuteur cible, la durée du discours (mesurée en secondes) est un facteur important pour l'attaquant pour construire le modèle PT et détermine l'efficacité des PT-AE. La figure 6 montre les TPR des PT-AE utilisant les 3 types de porteurs sous différents niveaux de connaissance des attaques (2, 4, 8 et 12 secondes). On observe sur la figure 6 que les TPR de toutes les porteuses AE augmentent en donnant plus de connaissances sur la parole du locuteur cible. Par exemple, le TPR du support environnemental sonore augmente considérablement de 0,14 (niveau de 4 secondes) à 0,25 (niveau de 8 secondes), puis légèrement jusqu'à 0,259 (niveau de 12 secondes).
Notez que le support environnemental sain dans les trois types a le TPR le plus élevé à chaque niveau de connaissance, ce qui est cohérent avec les résultats de la figure 5 et du tableau IV. Nous voyons également que la porteuse torsadée atteint le deuxième TPR le plus élevé, tandis que la porteuse de bruit a le TPR le plus bas. En résumé, nos résultats TPR montrent que nous pouvons baser les sons de l’environnement pour générer des PT-AE afin d’améliorer leur transférabilité vers un modèle cible boîte noire.
V - Attaques PT-AE optimisées par boîte noire
Dans cette section, nous proposons un mécanisme de génération PT-AE optimisé pour attaquer un modèle cible boîte noire. Nous étudions d’abord les TPR des PT-AE générés à partir de porteurs combinés, puis formulons une attaque en deux étapes pour générer des PT-AE contre le modèle cible.
A. Combinaison de transporteurs pour des PT-AE optimisés
Les résultats de la figure 6 révèlent que le support de bruit environnemental atteint le TPR le plus élevé et devrait être un bon choix pour générer des PT-AE. Mais l’utilisation du support sonore environnemental ne nous exclut pas de modifier davantage la fonction auditive du support ou d’y ajouter du bruit supplémentaire (par exemple, une attaque en phase d’enrôlement [39] a utilisé à la fois les sons environnementaux et le bruit). En d’autres termes, il existe un moyen potentiel de combiner le support sonore environnemental avec une méthode de modification des caractéristiques ou d’ajout de bruit pour améliorer encore le TPR.
Nous considérons deux types supplémentaires de porteurs : (i) les sons environnementaux déformés, et la manipulation de la hauteur [113] ou du rythme [44] est un moyen simple de modifier les caractéristiques des sons environnementaux. Nous suivons la même procédure de torsion des caractéristiques dans la section IV-C2 pour modifier les caractéristiques de hauteur et de rythme des sons environnementaux afin de générer des PTAE. (ii) Sons environnementaux basés sur le bruit. Nous ajoutons d’abord des sons environnementaux au discours original, puis utilisons la procédure d’attaque sonore de la section IV-C2 pour générer des PT-AE.

TABLEAU IV : Taux de correspondance entre les modèles de substitution et les modèles cibles.
 Fig. 6 : TPR des transporteurs avec différents niveaux de connaissance des attaques.
Fig. 6 : TPR des transporteurs avec différents niveaux de connaissance des attaques.
La figure 7 montre les TPR de divers PT-AE générés sur la base de (i) l'ajout de bruit, (ii) la torsion du rythme et (iii) la torsion de la hauteur d'un type de sons environnementaux. On peut constater que le TPR est sensible au choix des sons environnementaux. Par exemple, les sons de musique ne semblent pas très efficaces pour augmenter les TPR même avec des fonctionnalités tordues. Il est à noter que les sons naturels ont des TPR globalement plus élevés que les autres types de supports. Par exemple, l'utilisation des sons du ruisseau peut atteindre 0,29 TPR par rapport à l'alarme (0,25), au coq (0,26) et au Rock2 (0,16) dans l'ensemble de données existant [47]. De plus, la figure 7 illustre l'avantage uniforme de modifier la hauteur du son ambiant plutôt que de modifier le rythme et d'ajouter du bruit. Par exemple, en s'appuyant sur les sons de la grêle, la torsion de la fonction de hauteur obtient un TPR de 0,26, nettement supérieur à la torsion du rythme (0,18) et à l'ajout de bruit (0,05). De plus, la figure 7 montre que l'ajout de bruit est le moyen le moins efficace d'améliorer le TPR. Sur la base des résultats de la figure 7, nous envisageons de générer des PT-AE par rapport à un modèle cible de boîte noire en modifiant la fonction de hauteur des sons environnementaux.
B. Formulation d'attaque en boîte noire en deux étapes
Nous formulons maintenant la stratégie d’attaque PT-AE en boîte noire contre un locuteur cible dans un modèle de reconnaissance du locuteur cible. La stratégie d'attaque se compose de deux étapes.
Dans la première étape, l'attaquant doit déterminer un ensemble de sons environnementaux candidats, car il existe un large éventail de sons environnementaux disponibles et tous ne peuvent pas être efficaces contre le locuteur cible (comme le montre la figure 7). À cette fin, nous construisons d’abord un modèle de substitution PT pour l’attaquant, évaluons le TPR de chaque type de sons environnementaux sur la base du modèle de substitution et choisissons K sons avec les meilleurs TPR pour former l’ensemble candidat. Ensuite, nous prétraitons chaque son environnemental dans l'ensemble candidat en décalant sa hauteur pour obtenir son meilleur TPR, et obtenons un nouvel ensemble candidat de K sons décalés, noté {δk}k∈[1,K].

Fig. 7 : TPR de différents supports optimisés.

VI - Évaluations expérimentales
Dans cette section, nous mesurons les impacts de notre attaque PT-AE dans des contextes réels. Nous décrivons d’abord nos configurations, puis présentons et discutons les résultats expérimentaux.
A. Paramètres expérimentaux
Les paramètres de l'attaque PT-AE : Nous sélectionnons 3 modèles CNN et 3 modèles TDNN pour construire N = 6 modèles PT avec différents paramètres à assembler dans (5). Chaque modèle PT possède la même connaissance d'une phrase (discours de 8 secondes) du locuteur cible, qui est sélectionnée parmi les ensembles de données LibriSpeech [87] ou VoxCeleb1 [83]. Nous choisissons au hasard 6 à 16 haut-parleurs dans l'ensemble de données VCTK comme autres haut-parleurs pour construire chaque modèle PT. Nous choisissons K = 50 porteuses parmi les 200 porteuses sonores environnementales dans [47] pour former l'ensemble candidat pour l'attaquant et pouvons décaler la hauteur d'un son vers le haut/bas jusqu'à 25 demi-tons. Le seuil d'énergie totale ϵ est fixé à 0,08.

Systèmes de reconnaissance de locuteurs cibles : nous visons à évaluer les attaques contre deux principaux types de systèmes de reconnaissance de locuteurs : i) évaluations de lignes numériques : nous transmettons directement les AE aux systèmes open source au format de fichier audio numérique (PCM WAV 16 bits) pour évaluer l’impact de l’attaque. ii) évaluations en direct : nous effectuons des injections d'attaques en direct sur les appareils intelligents du monde réel.
Paramètres d'évaluation : (i) Efficacité de l'attaque : nous utilisons le taux de réussite de l'attaque (ASR) pour évaluer le pourcentage d'AE qui peuvent être reconnus avec succès comme locuteur cible dans un système de reconnaissance du locuteur. (ii) Qualité de perception : nous évaluons la qualité de perception d'un AE via la métrique du SRS.
B. Évaluations des attaques contre les lignes numériques
Configurations de lignes numériques : nous envisageons de choisir 4 modèles cibles différents parmi les modèles statistiques, c'est-à-dire GMM-UBM et ivector-PLDA [5], et basés sur DNN, c'est-à-dire DeepSpeaker [68] et ECAPA-TDNN [41]. Pour augmenter la diversité des modèles cibles, nous visons à choisir 3 hommes et 3 femmes parmi LibriSpeech et VoxCeleb1. Pour chaque sexe, nous sélectionnons au hasard 1 ou 2 locuteurs de LibriSpeech puis sélectionnons au hasard le(s) autre(s) de VoxCeleb1. Nous choisissons un discours d'environ 15 secondes de chaque locuteur pour nous inscrire avec chaque modèle de reconnaissance du locuteur. Les performances de chaque modèle de reconnaissance du locuteur cible sont présentées à l'annexe C.

Fig. 8 : Évaluation sur différents niveaux de connaissance des attaques.
Résultats des attaques de ligne numérique : dans les évaluations de ligne numérique, nous mesurons les performances de chaque stratégie d'attaque en générant 240 AE (40 AE pour chaque locuteur cible) par rapport à chaque modèle de reconnaissance du locuteur cible. Nous séparons les résultats selon le scénario intragenre (c'est-à-dire que le locuteur d'origine dont le discours est utilisé pour la génération AE est du même sexe que le locuteur cible) et le scénario inter-genre (les locuteurs d'origine et cible ne sont pas du même sexe, ce qui indique plus caractéristiques vocales distinctes). Nous évaluons également les attaques contre trois tâches : CSI, OSI et SV.
Le tableau V montre les ASR et SRS des AE générés par notre stratégie d'attaque PT-AE, par rapport à d'autres stratégies d'attaque, contre les tâches CSI, OSI et SV. Il ressort du tableau V que dans le scénario intra-genre, l'attaque PT-AE et QFA2SR (par exemple, 60,2 % pour l'attaque PT-AE et 40,0 % pour QFA2SR) peuvent atteindre des ASR moyens plus élevés (sur les trois tâches) que les autres. attaques (par exemple, 11,3 % pour FakeBob, 19,2 % pour Occam et 29,9 % pour Smack). Dans le même temps, les résultats du SRS moyen révèlent que la qualité de perception de l'attaque PT-AE (par exemple, 4,1 pour l'attaque PT-AE et 3,1 pour Smack) est meilleure que celle des autres attaques (par exemple, 2,3 pour QFA2SR, 2,1 pour Occam). , et 2.9 pour FakeBob). De plus, on peut observer que dans le scénario intergenre, les ASR et SRS deviennent généralement pires. Par exemple, l’ASR de FakeBob passe de 11,3 % à 6,9 % du scénario intra-genre à inter-genre. Mais nous pouvons voir que notre attaque PT-AE est toujours efficace en termes d'ASR moyen (par exemple, 54,6 % pour l'attaque PT-AE contre 29,7 % pour QFA2SR) et de SRS moyen (par exemple, 3,9 pour l'attaque PT-AE contre 3,2 pour l'attaque PT-AE). Claque). Les résultats du tableau V démontrent que l'attaque PT-AE est la plus efficace pour obtenir à la fois le succès de l'attaque boîte noire et la qualité de la perception.
C. Impacts des niveaux de connaissance des attaques
1) Impacts de la longueur de la parole sur l'efficacité de l'attaque : par défaut, nous construisons chaque modèle PT dans notre attaque en utilisant un échantillon de parole de 8 secondes provenant du locuteur cible. Nous nous intéressons à la manière dont les connaissances de l’attaquant affectent l’efficacité du PT-AE. Nous supposons que l’attaquant connaît le discours du locuteur cible entre 2 et 16 secondes et construit différents modèles PT basés sur ces différentes connaissances pour créer des PT-AE.
Analyse des résultats : la figure 8 montre les ASR des PT-AE selon différents niveaux de connaissances. Nous pouvons voir que davantage de connaissances peuvent augmenter l’ASR de l’attaquant. Lorsque la connaissance de l'attaque commence à augmenter de 2 à 8 secondes, l'ASR augmente considérablement (par exemple, de 21,3 % à 55,2 % contre l'OSI dans le scénario intra-genre). Lorsqu'il continue d'augmenter jusqu'à 16 secondes, l'ASR présente une légère augmentation. Une explication potentielle est que l'ASR peut être influencé par les différences d'architecture et de données de formation entre les modèles de substitution et cibles. Pendant ce temps, la méthode VC one-shot pourrait également atteindre un goulot d'étranglement en termes de performances lors de la conversion d'échantillons de perroquets en utilisant une parole encore plus longue. De plus, l’augmentation de la longueur de la parole n’indique pas toujours une augmentation de la diversité des phonèmes, ce qui peut également être important dans l’évaluation de la parole [81], [22]. Des études existantes [75], [104] ont souligné que les phonèmes représentent une caractéristique importante de l'empreinte vocale pour entraîner le modèle VC. Ainsi, nous visons à explorer davantage comment la diversité des phonèmes (en plus de la longueur des phrases) peut influencer l'ASR.

TABLEAU V : L'évaluation des différentes attaques en ligne numérique.
2) Impacts de la diversité des phonèmes : Puisqu'il n'existe pas de définition claire et uniforme de la diversité des phonèmes dans les études précédentes de VC [75], [104], nous la définissons comme le nombre de phonèmes uniques présents dans un segment de parole donné. Il convient de noter que même si certains phonèmes peuvent apparaître plusieurs fois dans le segment, chacun n'est pris en compte qu'une seule fois dans la diversité des phonèmes. Cette approche est adoptée car, du point de vue d’un attaquant, les phonèmes uniques ont plus de valeur que les phonèmes répétés. Alors que les phonèmes uniques apportent des caractéristiques d'empreinte vocale distinctes à un modèle VC, les phonèmes répétés peuvent être facilement reproduits et offrent moins de caractère distinctif (75).
Pour évaluer l'impact de la diversité des phonèmes sur l'ASR, nous choisissons des échantillons de parole de locuteurs cibles qui ont des diversités de phonèmes différentes mais sont de même durée (mesurée en secondes). D'après nos observations dans des ensembles de données existants (par exemple, LibriSpeech), un échantillon de parole plus court peut présenter une diversité de phonèmes plus élevée qu'un échantillon de parole plus long. Cela nous permet de sélectionner des échantillons de parole avec des niveaux de diversité de phonèmes significativement différents sous la même contrainte de longueur de parole.
Nous établissons des groupes de diversité phonémique faible et élevée dans des segments vocaux de même longueur pour mieux comprendre l'impact de la diversité phonémique sur l'efficacité des attaques. En particulier, pour chaque niveau de longueur de parole (par exemple 8 secondes) dans un ensemble de données, nous classons d'abord l'échantillon de parole de chaque locuteur cible par diversité de phonèmes, puis regroupons la moitié supérieure de tous les échantillons (avec des valeurs élevées de diversité de phonèmes). comme groupe à forte diversité de phonèmes et la moitié inférieure comme groupe à faible diversité. De cette manière, le groupe à faible diversité de phonèmes a moins de phonèmes distinctifs que le groupe à forte diversité, offrant suffisamment de différences en termes de connaissances sur les attaques pour comparaison.
Nous construisons notre ensemble de discours de connaissances sur les attaques en utilisant les échantillons de parole de 3 locuteurs masculins et féminins de LibriSpeech et VoxCeleb1, conformément aux configurations de ligne numérique détaillées dans la section VI-B. Notre objectif est de capturer diverses diversités de phonèmes sous différentes longueurs de parole. Le tableau VI montre la diversité moyenne des phonèmes et le nombre total de phonèmes des échantillons de parole dans les groupes à faible et forte diversité sous le même niveau de longueur de parole (2 à 16 secondes). Le tableau VI démontre que la diversité des phonèmes augmente à mesure que la longueur de la parole augmente. De plus, nous constatons que la diversité des phonèmes peut évidemment varier même lorsque le nombre total de phonèmes est similaire. Pour la catégorie de 8 secondes, le groupe à faible diversité de phonèmes a une diversité moyenne de 18,6, tandis que le groupe à forte diversité en a 24,2. Malgré cette différence, ils ont un nombre total de phonèmes similaire (80,4 contre 80,6).
Ensuite, sous chaque niveau de longueur de parole (2, 4, 8, 12, 16 secondes) pour chaque locuteur cible (3 locuteurs masculins et 3 locuteurs féminins), nous utilisons des échantillons de parole des groupes à diversité de phonèmes faible et élevée pour l'entraînement des perroquets et générons 90 PT-AE de chaque groupe. Cela a abouti à un total de 5 400 PT-AE pour l’évaluation de la diversité des phonèmes.

TABLEAU VI : Diversités de phonèmes avec différentes longueurs de parole.
Analyse des résultats : la figure 9 montre les ASR des PT-AE générés à partir de groupes à faible et forte diversité par rapport aux tâches CSI, OSI et SV. Il ressort de la figure que les PT-AE basés sur un groupe à forte diversité ont un ASR plus élevé que ceux à faible diversité dans les scénarios intra-genre et inter-genre. Par exemple, les ASR intergenres sont de 47,70 % (faible diversité) contre 55,56 % (forte diversité). La plus grande différence d'ASR est observée dans le cas de 4 secondes dans la tâche CSI pour le scénario intragenre, avec une différence maximale de 10,0 %. Les résultats montrent que l’utilisation d’échantillons vocaux présentant une grande diversité de phonèmes pour l’entraînement des perroquets peut effectivement améliorer l’efficacité des attaques des PT-AE.
De plus, nous calculons via les coefficients de Pearson [54] la corrélation de l’ASR avec chacune des méthodes pour mesurer le niveau de connaissance de l’attaque, notamment la mesure de la longueur de parole, le comptage du nombre total de phonèmes et l’utilisation de la diversité des phonèmes. Nous constatons que la diversité des phonèmes atteint le coefficient de Pearson le plus élevé, soit 0,9692, par rapport à l'utilisation de la longueur de parole (0,9341) et au comptage du nombre total de phonèmes (0,9574). En conséquence, la diversité des phonèmes pour mesurer la connaissance de l’attaque est la plus liée à l’efficacité de l’attaque, tandis que l’utilisation de la longueur de parole ou du nombre total de phonèmes peut toujours être considérée comme adéquate car ils ont tous deux des coefficients de Pearson élevés.

Fig. 9 : Évaluation de la diversité des phonèmes.

TABLEAU VII : Résultats expérimentaux sur les appareils intelligents.
D. Évaluations des attaques aériennes
Ensuite, nous nous concentrons sur l’attaque des appareils intelligents dans le scénario en direct. Nous considérons trois appareils intelligents populaires : Amazon Echo Plus [8], Google Home Mini[11] et Apple HomePod (Siri) [3]. Pour l'inscription des locuteurs, nous utilisons 3 locuteurs masculins et 3 locuteurs féminins de la plateforme de synthèse vocale de Google pour générer le discours d'inscription pour chaque appareil. Nous utilisons uniquement un discours de 8 secondes de chaque locuteur cible pour construire nos modèles PT. Nous considérons les tâches OSI et SV sur Amazon Echo, ainsi que la tâche SV sur Apple HomePod et Google Home. De même, nous évaluons les différentes attaques dans des scénarios intra-genres et intergenres. Pour chaque stratégie d'attaque, nous générons et diffusons 24 AE à l'aide d'un haut-parleur JBL Clip3 sur chaque appareil intelligent à une distance de 0,5 mètre.
Analyse des résultats : le tableau VII compare différentes méthodes d'attaque contre les appareils intelligents sous diverses tâches. Nous pouvons voir que notre attaque PT-AE peut atteindre des ASR moyens de 58,3 % (intra-genre) et 47,9 % (inter-genre) et en même temps des SRS moyens de 4,77 (intra-genre) et 4,45 (intergenre). En revanche, QFA2SR a les deuxièmes meilleurs ASR de 31,3 % (intra-genre) et 22,92 % (inter-genre) ; cependant, sa qualité de perception est nettement inférieure à celle de l'attaque PT-AE et de Smack, par exemple 2,75 (QFA2SR) contre 4,51 (Smack) contre 4,77 (attaque PT-AE) dans le scénario intra-genre. Nous constatons également que FakeBob et Occam semblent inefficaces avec l'injection en direct, car aucun ASR n'est observé contre Amazon Echo et Google Home. Dans l’ensemble, les résultats en direct démontrent que les PT-AE générés par l’attaque PT-AE peuvent atteindre un ASR élevé avec une bonne qualité de perception. De plus, nous avons également évalué la robustesse des PT-AE à distance. Les résultats sont disponibles dans le tableau X de l'annexe D.
E. Contribution de chaque composante à l'ASR
Comme la génération PT-AE implique trois composants de conception majeurs, notamment la formation des perroquets, le choix des porteurs et l'apprentissage d'ensemble, pour améliorer la transférabilité globale, nous proposons d'évaluer la contribution de chaque composant individuel à l'ASR. Notre méthodologie est similaire à la stratégie One-at-a-time (OAT) de [44]. Plus précisément, nous supprimons et remplaçons chaque composant de conception par une approche de base alternative (en tant qu'attaque de base), tout en conservant les autres paramètres identiques lors de la génération des PT-AE, puis comparons l'ASR résultant avec l'ASR de PT-AE sans suppression. AE (c'est-à-dire les PT-AE générés sans supprimer/remplacer aucun composant de conception). Grâce à cette méthode, nous pouvons déterminer comment chaque composant contribue à l’efficacité globale de l’attaque.
Nous utilisons la même configuration d'attaque en direct que celle décrite dans la section VI-D. Pour chaque attaque de base, nous élaborons 96 AE pour des scénarios intra et inter-genres. Ces AE sont diffusés sur chaque appareil intelligent par le même haut-parleur à la même distance. Nous présentons le dispositif expérimental et les résultats concernant l'évaluation de la contribution de chaque composant de conception comme suit.

TABLEAU VIII : ASR avec suppression de chaque composant de conception.
1) Entraînement du perroquet : plutôt que d'entraîner les modèles de substitution avec le discours du perroquet, nous utilisons directement le discours d'une phrase (8 secondes) du locuteur cible pour l'inscription auprès des modèles de substitution. Ces modèles de substitution, que nous appelons modèles sans entraînement de perroquet (non PT), sont formés sur les ensembles de données qui excluent les échantillons de parole des locuteurs cibles.
Résultats : Comme le montre le tableau VIII (la ligne « Pas de PT »), nous observons une différence significative d'ASR entre les AE non basés sur le PT et les PT-AE sans suppression. Par exemple, dans la tâche AmazonSV, les PT-AE atteignent un ASR de 54,2 %, soit 20,9 % de plus que l'ASR de 33,3 % des AE non-PT. Dans l’ensemble, l’ASR moyen des PT-AE est 21,8 % plus élevé que celui des AE non-PT. Cet écart de performance important est principalement comblé par l’adoption d’un dressage de perroquets.
2) Support sonore environnemental : pour comprendre la contribution du support sonore environnemental à caractéristiques tordues, nous utilisons deux attaques de base liées au bruit et aux porteuses tordues à caractéristiques. i) Porteurs de bruit, nous utilisons l'attaque PGD pour générer les AE sur la base des modèles PT via un apprentissage d'ensemble, en définissant ϵ = 0,05 pour contrôler la norme L∞. ii) Présentez des porteuses tordues, comme indiqué dans la section V-A, nous décalons la hauteur du discours original vers le haut ou vers le bas jusqu'à 25 demi-tons pour créer un ensemble tordu. Nous utilisons cet ensemble pour résoudre le problème de (5) en trouvant les poids optimaux pour les porteurs à pas torsadé, avec un seuil d'énergie totale de ϵ = 0,08.
Résultats : Le tableau VIII (les lignes « pas de bruit environnemental ») indique que les PT-AE basés sur le bruit environnemental détiennent un net avantage sur les autres transporteurs en termes d'efficacité des attaques. Nous notons que lorsque nous excluons les porteuses sonores environnementales tordues et que nous nous appuyons uniquement sur le bruit ou sur les porteuses tordues, l'ASR moyen chute de 23,9 % (par rapport à la porteuse de bruit) et de 19,8 % (par rapport à la porteuse tordue). Ces résultats montrent que l’utilisation de sons environnementaux déformés peut améliorer considérablement l’efficacité de l’attaque.

Fig. 10 : Évaluation humaine des AE.
3) Apprentissage d'ensemble : nous notons que notre modèle basé sur l'ensemble dans (5) combine plusieurs modèles CNN et TDNN. Pour évaluer la contribution de l'apprentissage d'ensemble, nous concevons deux ensembles d'expériences. Tout d'abord, nous remplaçons le modèle basé sur l'ensemble dans (5) par un seul modèle PT-CNN ou PT-TDNN pour comparer les ASR. Deuxièmement, nous remplaçons (5) par un modèle basé sur un ensemble, qui se compose uniquement de plusieurs modèles de substitution (en particulier 6 dans les expériences) sous la même architecture CNN ou TDNN (c'est-à-dire pas d'assemblage entre différentes architectures).
Résultats : Nous pouvons observer dans le tableau VIII (lignes « apprentissage d'ensemble non ou insuffisant ») que les modèles uniques PT-CNN et PTTDNN n'ont que des ASR moyens de 31,3 % et 32,3 %, respectivement. Si nous adoptons l'apprentissage d'ensemble mais combinons des modèles de substitution sous la même architecture, les ASR moyens peuvent être améliorés à 43,8 % et 45,8 % sous plusieurs modèles PT-CNN et PT-TDNN, respectivement. En revanche, les PT-AE non supprimés atteignent l'ASR moyen le plus élevé de 53,1 %.
En résumé, les trois éléments clés de la conception des PT-AE, à savoir l'entraînement des perroquets, les sons environnementaux déformés et l'apprentissage d'ensemble, améliorent l'ASR moyen de 21,8 %, 21,9 % et 21,3 %, respectivement, par rapport à leur individu. remplacements de base. En conséquence, ils sont tous importants pour l’attaque par boîte noire et ont une contribution à peu près égale à l’ASR global.
F. Étude humaine des EI générés lors d’expériences
Nous avons utilisé la métrique du SRS basée sur la prédiction de régression basée sur l'étude humaine de la section IV-B pour évaluer que les PT-AE ont une meilleure qualité de perception que les AE générés par d'autres méthodes d'attaque dans les évaluations expérimentales. Nous menons maintenant une nouvelle série d'études sur l'homme pour voir si les PT-AE générés dans les expériences sont effectivement mieux notés que les autres AE par les participants humains. Plus précisément, nous avons recruté 45 étudiants volontaires supplémentaires (22 femmes et 23 hommes), âgés de 18 à 35 ans. Ils participent tous pour la première fois et n'ont aucune connaissance de l'étude humaine précédente de la section IV-B. En suivant la même procédure, nous demandons à chaque volontaire d'évaluer chaque paire d'échantillons originaux et PT-AE.
La figure 10 montre les scores moyens de parole humaine de Smack, QFA2SR et de notre attaque. Nous pouvons voir que les PT-AE générés par notre attaque sont mieux notés que Smack et QFA2SR. Dans le scénario intra-genre, le score humain moyen de notre attaque est de 5,39, ce qui est supérieur à Smack (4,61) et QFA2SR (3,62). Le score de chaque méthode diminue légèrement dans le scénario inter-genre. Les résultats concordent avec les conclusions du SRS dans le tableau VII. Nous constatons également que les scores SRS sont proches des scores humains. Dans le scénario intergenre, SRS prédit la qualité perceptuelle de nos PT-AE à 4,45, proche de la moyenne humaine de 4,8. Les résultats de la figure 10 confirment en outre que les PT-AE ont une meilleure qualité de perception que les AE générés par d'autres méthodes.
G. Discussions
Préoccupations éthiques et divulgation responsable : nos expériences sur les appareils intelligents n’impliquaient aucune information privée de qui que ce soit. Toutes les expériences ont été mises en place dans notre laboratoire local. Nous avons fait part de nos découvertes aux fabricants (Amazon, Apple et Google). Tous les fabricants ont remercié nos efforts de recherche et de divulgation visant à protéger leurs services. Google a répondu rapidement à nos enquêtes, confirmant l'existence d'un problème de non-concordance vocale et a classé l'affaire en déclarant que l'attaque nécessitait l'ajout d'un nœud malveillant. Nous sommes toujours en communication avec Amazon et Apple.
Nous discutons également des stratégies de défense potentielles contre les PTAE. En raison du nombre limité de pages, nous avons présenté la discussion de la défense à l’Annexe E.
VII - Travaux connexes
Attaques en boîte blanche : attaques audio contradictoires [28], [114], [72], [101], [105], [32], [43], [118], [43], [29], [118 ] peuvent être classés en attaques boîte blanche et boîte noire en fonction de leur niveau de connaissance des attaques. Les attaques en boîte blanche [28], [95] supposaient la connaissance du modèle cible et exploitaient les informations de gradient du modèle cible pour générer des AE très efficaces. Certaines études récentes visaient à améliorer le caractère pratique des attaques en boîte blanche [72], [52] en ajoutant la perturbation au signal vocal original sans synchronisation, tout en supposant toujours une connaissance presque complète du modèle cible.
Attaques boîte noire basées sur des requêtes : les attaques boîte noire existantes [29], [118], [101], [105], [74], [113] supposaient qu'il n'y avait aucun accès à la connaissance interne des modèles cibles, et la plupart des attaques noires Les attaques -box tentaient de connaître le modèle cible via une stratégie de requête (ou de sondage). Les attaques basées sur des requêtes [29], [43], [118], [113], [74] devaient interagir avec le modèle cible pour obtenir les scores de prédiction internes [29], [105], [32], [ 113] ou des résultats d’étiquettes dures [118], [74]. Un grand nombre de requêtes ont été nécessaires pour que l’attaque par boîte noire soit efficace. Par exemple, Occam [118] avait besoin de plus de 10 000 requêtes pour atteindre un ASR élevé. Cela rend la stratégie d’attaque difficile à lancer, en particulier dans les scénarios en direct. L'attaque PT-AE ne nécessite aucun sondage sur le modèle cible.
Attaques de boîte noire basées sur le transfert : les attaques basées sur le transfert [17], [44], [30] supposaient généralement qu'il n'y avait aucune interaction ou qu'une analyse limitée [32] du modèle cible. Par exemple, Kenansville [17] a manipulé le phonème du discours pour réaliser une attaque non ciblée. QFA2SR [30] s'est concentré sur la construction de modèles de substitution avec des stratégies d'ensemble spécifiques pour améliorer la transférabilité des AE en supposant connaître plusieurs échantillons de parole de tous les locuteurs inscrits du modèle cible. Par rapport à QFA2SR, nous minimisons davantage les connaissances et ne supposons pour l’attaquant qu’un court échantillon de parole du locuteur cible. Même avec les connaissances les plus limitées en matière d’attaques, nous proposons une nouvelle stratégie PT-AE qui crée des AE plus efficaces contre le modèle cible.
Attaques audio prenant en compte la qualité de perception : Certaines études récentes [95], [52], [74] ont exploité la fonction psychoacoustique pour optimiser les porteuses et améliorer la perception des EI. Pendant ce temps, [44], [113] ont manipulé les caractéristiques d'un signal audio pour créer des AE avec une bonne qualité de perception. De plus, il existe des stratégies d’attaque audio [116], [26], [16], [114] axées sur l’amélioration de la furtivité des AE. Par exemple, l’attaque des dauphins [116] utilisait des ultrasons pour générer des AE imperceptibles. L'étude humaine dans ce travail définit la métrique du SRS pour quantifier la qualité de la parole en utilisant une procédure de régression similaire motivée par le modèle qDev de [44] qui a été créé pour mesurer la qualité de la musique. Nous concevons ensuite un nouveau cadre TPR basé sur la métrique SRS pour évaluer conjointement à la fois la transférabilité et la perception des PT-AE.
VIII - Conclusion
Dans ce travail, nous avons étudié l’utilisation de la connaissance minimale du discours d’un locuteur cible pour attaquer un modèle de reconnaissance du locuteur cible en boîte noire. Nous avons évalué de manière approfondie la faisabilité de l'utilisation de méthodes VC de pointe pour générer des échantillons de parole de perroquet afin de construire un modèle de substitution PT et les méthodes de génération de PT-AE. Il est démontré que les PT-AE peuvent être transférés efficacement vers un modèle cible de type boîte noire et que l'attaque PT-AE proposée a permis d'obtenir des ASR plus élevés et une meilleure qualité de perception que les méthodes existantes contre les modèles de reconnaissance de locuteurs numériques et les appareils intelligents commerciaux dans des conditions de sur- scénarios aériens.
IX - Références
[1] Alexa Voice ID. https://www.amazon.com/gp/help/customer/display. html?nodeId=GYCXKY2AB2QWZT2X/, 2022. Accessed: 2022-12- 13.
[2] Amazon Alexa. https://developer.amazon.com/en-US/alexa, 2022. Accessed: 2022-01-07.
[3] Apple Siri. https://support.apple.com/en-us/HT204389/, 2022. Accessed: 2022-12-13.
[4] Fidelity-MyVoice. https://www.fidelity.com/security/fidelity-myvoice/ overview/, 2022. Accessed: 2022-12-13.
[5] Kaldi. https://github.com/kaldi-asr/kaldi/, 2022. Accessed: 2022-12- 13.
[6] Tencent VPR. https://cloud.tencent.com/product/vpr/, 2022. Accessed: 2022-12-13.
[7] AGAIN-VC. https://github.com/KimythAnly/AGAIN-VC/, 2023. Accessed: 2023-01-07.
[8] Amazon Activities. https://www.digitaltrends.com/news/ alexa-check-my-balance-amazon-echo-can-now-bank-for-you//, 2023. Accessed: 2023-04-18.
[9] AutoVC. https://github.com/auspicious3000/autovc/, 2023. Accessed: 2023-01-07.
[10] FreeVC. https://github.com/OlaWod/FreeVC/, 2023. Accessed: 2023- 01-07.
[11] Google Home. https://home.google.com/welcome/, 2023. Accessed: 2023-5-05.
[12] Microsoft Azure. https://azure.microsoft.com/en-ca/products/ cognitive-services/speech-to-text//, 2023. Accessed: 2023-02-07.
[13] PPG-VC. https://github.com/liusongxiang/ppg-vc/, 2023. Accessed: 2023-01-07.
[14] Semitone. https://en.wikipedia.org/wiki/Semitone/, 2023. Accessed: 2023-04-20.
[15] VQMIVC. https://github.com/Wendison/VQMIVC/, 2023. Accessed: 2023-01-07.
[16] Hadi Abdullah, Washington Garcia, Christian Peeters, Patrick Traynor, Kevin RB Butler, and Joseph Wilson. Practical hidden voice attacks against speech and speaker recognition systems. In Proc. of NDSS, 2019.
[17] Hadi Abdullah, Muhammad Sajidur Rahman, Washington Garcia, Logan Blue, Kevin Warren, Anurag Swarnim Yadav, Tom Shrimpton, and Patrick Traynor. Hear” no evil”, see” kenansville”: Efficient and transferable black-box attacks on speech recognition and voice identification systems. In Proc. of IEEE S&P, 2021.
[18] Alankrita Aggarwal, Mamta Mittal, and Gopi Battineni. Generative adversarial network: An overview of theory and applications. International Journal of Information Management Data Insights, 1(1):100004, 2021.
[19] Supraja Anand, Lisa M Kopf, Rahul Shrivastav, and David A Eddins. Objective indices of perceived vocal strain. Journal of Voice, 33(6):838–845, 2019.
[20] Yogesh Balaji, Tom Goldstein, and Judy Hoffman. Instance adaptive adversarial training: Improved accuracy tradeoffs in neural nets. arXiv preprint arXiv:1910.08051, 2019.
[21] Mikołaj Binkowski, Jeff Donahue, Sander Dieleman, Aidan Clark, ´ Erich Elsen, Norman Casagrande, Luis C Cobo, and Karen Simonyan. High fidelity speech synthesis with adversarial networks. arXiv preprint arXiv:1909.11646, 2019.
[22] Shelley B Brundage and N. Ratner. Measurement of stuttering frequency in children’s speech. Journal of Fluency Disorders, 14:351– 358, 1989.
[23] Kate Bunton, Raymond D Kent, Joseph R Duffy, John C Rosenbek, and Jane F Kent. Listener agreement for auditory-perceptual ratings of dysarthria. 2007.
[24] Lei Cai, Hongyang Gao, and Shuiwang Ji. Multi-stage variational auto-encoders for coarse-to-fine image generation. In Proceedings of the 2019 SIAM International Conference on Data Mining, pages 630– 638. SIAM, 2019.
[25] Qi-Zhi Cai, Min Du, Chang Liu, and Dawn Song. Curriculum adversarial training. In Proc. of IJCAI, 2018.
[26] Nicholas Carlini, Pratyush Mishra, Tavish Vaidya, Yuankai Zhang, Micah Sherr, Clay Shields, David Wagner, and Wenchao Zhou. Hidden voice commands. In Proc. of USENIX Security, 2016.
[27] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In Proc. of IEEE S&P, 2017.
[28] Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. In Proc. of SPW, 2018.
[29] Guangke Chen, Sen Chen, Lingling Fan, Xiaoning Du, Zhe Zhao, Fu Song, and Yang Liu. Who is real bob? adversarial attacks on speaker recognition systems. In Proc. of IEEE S&P, 2021.
[30] Guangke Chen, Yedi Zhang, Zhe Zhao, and Fu Song. Qfa2sr: Queryfree adversarial transfer attacks to speaker recognition systems. arXiv preprint arXiv:2305.14097, 2023.
[31] Yen-Hao Chen, Da-Yi Wu, Tsung-Han Wu, and Hung-yi Lee. Againvc: A one-shot voice conversion using activation guidance and adaptive instance normalization. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5954–5958. IEEE, 2021.
[32] Yuxuan Chen, Xuejing Yuan, Jiangshan Zhang, Yue Zhao, Shengzhi Zhang, Kai Chen, and XiaoFeng Wang. Devil’s whisper: A general approach for physical adversarial attacks against commercial blackbox speech recognition devices. In Proc. of USENIX Security, 2020.
[33] Zhehuai Chen, Andrew Rosenberg, Yu Zhang, Gary Wang, Bhuvana Ramabhadran, and Pedro J Moreno. Improving speech recognition using gan-based speech synthesis and contrastive unspoken text selection. In Interspeech, pages 556–560, 2020.
[34] Ju-chieh Chou, Cheng-chieh Yeh, and Hung-yi Lee. One-shot voice conversion by separating speaker and content representations with instance normalization. arXiv preprint arXiv:1904.05742, 2019.
[35] Antonia Creswell, Tom White, Vincent Dumoulin, Kai Arulkumaran, Biswa Sengupta, and Anil A Bharath. Generative adversarial networks: An overview. IEEE signal processing magazine, 35(1):53–65, 2018.
[36] Frederic L Darley, Arnold E Aronson, and Joe R Brown. Differential diagnostic patterns of dysarthria. Journal of speech and hearing research, 12(2):246–269, 1969.
[37] Jesse Davis and Mark Goadrich. The relationship between precisionrecall and roc curves. In Proceedings of the 23rd international conference on Machine learning, pages 233–240, 2006.
[38] Najim Dehak, Patrick J Kenny, Reda Dehak, Pierre Dumouchel, and ´ Pierre Ouellet. Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(4):788– 798, 2010.
[39] Jiangyi Deng, Yanjiao Chen, and Wenyuan Xu. Fencesitter: Black-box, content-agnostic, and synchronization-free enrollment-phase attacks on speaker recognition systems. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 755– 767, 2022.
[40] Jiangyi Deng, Yanjiao Chen, Yinan Zhong, Qianhao Miao, Xueluan Gong, and Wenyuan Xu. Catch you and i can: Revealing source voiceprint against voice conversion. arXiv preprint arXiv:2302.12434, 2023.
[41] Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. Ecapatdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv preprint arXiv:2005.07143, 2020.
[42] Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9185–9193, 2018.
[43] Tianyu Du, Shouling Ji, Jinfeng Li, Qinchen Gu, Ting Wang, and Raheem Beyah. Sirenattack: Generating adversarial audio for endto-end acoustic systems. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, pages 357– 369, 2020.
[44] Rui Duan, Zhe Qu, Shangqing Zhao, Leah Ding, Yao Liu, and Zhuo Lu. Perception-aware attack: Creating adversarial music via reverse engineering human perception. In Proc. of ACM CCS, pages 905–919, 2022.
[45] Cesar Ferri, Peter Flach, and Jos ´ e Hern ´ andez-Orallo. Learning decision ´ trees using the area under the roc curve. In Icml, volume 2, pages 139– 146, 2002.
[46] Lianli Gao, Qilong Zhang, Jingkuan Song, Xianglong Liu, and Heng Tao Shen. Patch-wise attack for fooling deep neural network. In European Conference on Computer Vision, pages 307–322. Springer, 2020.
[47] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 776–780. IEEE, 2017.
[48] Laurent Girin, Simon Leglaive, Xiaoyu Bie, Julien Diard, Thomas Hueber, and Xavier Alameda-Pineda. Dynamical variational autoencoders: A comprehensive review. arXiv preprint arXiv:2008.12595, 2020.
[49] Tom Goldstein, Christoph Studer, and Richard Baraniuk. A field guide to forward-backward splitting with a fasta implementation. arXiv preprint arXiv:1411.3406, 2014.
[50] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
[51] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
[52] Hanqing Guo, Yuanda Wang, Nikolay Ivanov, Li Xiao, and Qiben Yan. Specpatch: Human-in-the-loop adversarial audio spectrogram patch attack on speech recognition. 2022.
[53] William Harvey, Saeid Naderiparizi, and Frank Wood. Conditional image generation by conditioning variational auto-encoders. arXiv preprint arXiv:2102.12037, 2021.
[54] Jan Hauke and Tomasz Kossowski. Comparison of values of pearson’s and spearman’s correlation coefficients on the same sets of data. Quaestiones geographicae, 30(2):87–93, 2011.
[55] Wei-Ning Hsu, Yu Zhang, Ron J Weiss, Heiga Zen, Yonghui Wu, Yuxuan Wang, Yuan Cao, Ye Jia, Zhifeng Chen, Jonathan Shen, et al. Hierarchical generative modeling for controllable speech synthesis. arXiv preprint arXiv:1810.07217, 2018.
[56] Wenbin Huang, Wenjuan Tang, Hongbo Jiang, Jun Luo, and Yaoxue Zhang. Stop deceiving! an effective defense scheme against voice impersonation attacks on smart devices. IEEE Internet of Things Journal, 9(7):5304–5314, 2021.
[57] Sergey Ioffe. Probabilistic linear discriminant analysis. In European Conference on Computer Vision, pages 531–542. Springer, 2006.
[58] Arindam Jati, Chin-Cheng Hsu, Monisankha Pal, Raghuveer Peri, Wael AbdAlmageed, and Shrikanth Narayanan. Adversarial attack and defense strategies for deep speaker recognition systems. Computer Speech & Language, 68:101199, 2021.
[59] Takuhiro Kaneko, Hirokazu Kameoka, Nobukatsu Hojo, Yusuke Ijima, Kaoru Hiramatsu, and Kunio Kashino. Generative adversarial networkbased postfilter for statistical parametric speech synthesis. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 4910–4914. IEEE, 2017.
[60] Takuhiro Kaneko, Hirokazu Kameoka, Kou Tanaka, and Nobukatsu Hojo. Cyclegan-vc2: Improved cyclegan-based non-parallel voice conversion. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6820–6824. IEEE, 2019.
[61] Takuhiro Kaneko, Hirokazu Kameoka, Kou Tanaka, and Nobukatsu Hojo. Stargan-vc2: Rethinking conditional methods for stargan-based voice conversion. arXiv preprint arXiv:1907.12279, 2019.
[62] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[63] Tom Ko, Vijayaditya Peddinti, Daniel Povey, and Sanjeev Khudanpur. Audio augmentation for speech recognition. In Sixteenth annual conference of the international speech communication association, 2015.
[64] Tom Ko, Vijayaditya Peddinti, Daniel Povey, Michael L Seltzer, and Sanjeev Khudanpur. A study on data augmentation of reverberant speech for robust speech recognition. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5220–5224. IEEE, 2017.
[65] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020.
[66] Alexandru Korotcov, Valery Tkachenko, Daniel P Russo, and Sean Ekins. Comparison of deep learning with multiple machine learning methods and metrics using diverse drug discovery data sets. Molecular pharmaceutics, 14(12):4462–4475, 2017.
[67] Kong Aik Lee, Qiongqiong Wang, and Takafumi Koshinaka. The coral+ algorithm for unsupervised domain adaptation of plda. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5821–5825. IEEE, 2019.
[68] Chao Li, Xiaokong Ma, Bing Jiang, Xiangang Li, Xuewei Zhang, Xiao Liu, Ying Cao, Ajay Kannan, and Zhenyao Zhu. Deep speaker: an end-to-end neural speaker embedding system. arXiv preprint arXiv:1705.02304, 2017.
[69] Jason Li, Ravi Gadde, Boris Ginsburg, and Vitaly Lavrukhin. Training neural speech recognition systems with synthetic speech augmentation. arXiv preprint arXiv:1811.00707, 2018.
[70] Jingyi Li, Weiping Tu, and Li Xiao. Freevc: Towards high-quality text-free one-shot voice conversion.
[71] Yuanchun Li, Ziqi Zhang, Bingyan Liu, Ziyue Yang, and Yunxin Liu. Modeldiff: testing-based dnn similarity comparison for model reuse detection. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 139–151, 2021.
[72] Zhuohang Li, Yi Wu, Jian Liu, Yingying Chen, and Bo Yuan. Advpulse: Universal, synchronization-free, and targeted audio adversarial attacks via subsecond perturbations. In Proc. of ACM CCS, pages 1121–1134, 2020.
[73] Jiadong Lin, Chuanbiao Song, Kun He, Liwei Wang, and John E Hopcroft. Nesterov accelerated gradient and scale invariance for adversarial attacks. arXiv preprint arXiv:1908.06281, 2019.
[74] Han Liu, Zhiyuan Yu, Mingming Zha, XiaoFeng Wang, William Yeoh, Yevgeniy Vorobeychik, and Ning Zhang. When evil calls: Targeted adversarial voice over ip network. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 2009–2023, 2022.
[75] Songxiang Liu, Yuewen Cao, Disong Wang, Xixin Wu, Xunying Liu, and Helen Meng. Any-to-many voice conversion with location-relative sequence-to-sequence modeling. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:1717–1728, 2021.
[76] Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. Delving into transferable adversarial examples and black-box attacks. arXiv preprint arXiv:1611.02770, 2016.
[77] Hui Lu, Zhiyong Wu, Dongyang Dai, Runnan Li, Shiyin Kang, Jia Jia, and Helen Meng. One-shot voice conversion with global speaker embeddings. In Interspeech, pages 669–673, 2019.
[78] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In Proc. of ICML Work Shop, 2017.
[79] Yuhao Mao, Chong Fu, Saizhuo Wang, Shouling Ji, Xuhong Zhang, Zhenguang Liu, Jun Zhou, Alex X Liu, Raheem Beyah, and Ting Wang. Transfer attacks revisited: A large-scale empirical study in real computer vision settings. arXiv preprint arXiv:2204.04063, 2022.
[80] Agnieszka Mikołajczyk and Michał Grochowski. Data augmentation for improving deep learning in image classification problem. In 2018 international interdisciplinary PhD workshop (IIPhDW), pages 117– 122. IEEE, 2018.
[81] M. Mines, Barbara F. Hanson, and J. Shoup. Frequency of occurrence of phonemes in conversational english. Language and Speech, 21:221 – 241, 1978.
[82] Gabriel Mittag, Babak Naderi, Assmaa Chehadi, and Sebastian Moller. Nisqa: A deep cnn-self-attention model for multidimensional ¨ speech quality prediction with crowdsourced datasets. arXiv preprint arXiv:2104.09494, 2021.
[83] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Voxceleb: a large-scale speaker identification dataset. arXiv preprint arXiv:1706.08612, 2017.
[84] Preeti Nagrath, Rachna Jain, Agam Madan, Rohan Arora, Piyush Kataria, and Jude Hemanth. Ssdmnv2: A real time dnn-based face mask detection system using single shot multibox detector and mobilenetv2. Sustainable cities and society, 66:102692, 2021.
[85] Mahesh Kumar Nandwana, Luciana Ferrer, Mitchell McLaren, Diego Castan, and Aaron Lawson. Analysis of critical metadata factors for the calibration of speaker recognition systems. In INTERSPEECH, pages 4325–4329, 2019.
[86] Phani Sankar Nidadavolu, Vicente Iglesias, Jesus Villalba, and Najim ´ Dehak. Investigation on neural bandwidth extension of telephone speech for improved speaker recognition. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6111–6115. IEEE, 2019.
[87] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
[88] Nicolas Papernot, Patrick McDaniel, and Ian Goodfellow. Transferability in machine learning: from phenomena to black-box attacks using adversarial samples. arXiv preprint arXiv:1605.07277, 2016.
[89] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia conference on computer and communications security, pages 506–519, 2017.
[90] Daniel S Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D Cubuk, and Quoc V Le. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv preprint arXiv:1904.08779, 2019.
[91] Sona Patel, Rahul Shrivastav, and David A Eddins. Perceptual distances of breathy voice quality: A comparison of psychophysical methods. Journal of Voice, 24(2):168–177, 2010.
[92] Luis Perez and Jason Wang. The effectiveness of data augmentation in image classification using deep learning. arXiv preprint arXiv:1712.04621, 2017.
[93] Daniel Povey, Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Yanmin Qian, Petr Schwarz, et al. The kaldi speech recognition toolkit. In IEEE 2011 workshop on automatic speech recognition and understanding, number CONF. IEEE Signal Processing Society, 2011.
[94] Kaizhi Qian, Yang Zhang, Shiyu Chang, Xuesong Yang, and Mark Hasegawa-Johnson. Autovc: Zero-shot voice style transfer with only autoencoder loss. In International Conference on Machine Learning, pages 5210–5219. PMLR, 2019.
[95] Yao Qin, Nicholas Carlini, Garrison Cottrell, Ian Goodfellow, and Colin Raffel. Imperceptible, robust, and targeted adversarial examples for automatic speech recognition. In Proc. of ICML, pages 5231–5240. PMLR, 2019.
[96] Douglas A Reynolds, Thomas F Quatieri, and Robert B Dunn. Speaker verification using adapted gaussian mixture models. Digital signal processing, 10(1-3):19–41, 2000.
[97] Ali Shafahi, Mahyar Najibi, Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S Davis, Gavin Taylor, and Tom Goldstein. Adversarial training for free! In Proc. of NIPS, 2019.
[98] Connor Shorten and Taghi M Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of big data, 6(1):1–48, 2019.
[99] David Snyder, Daniel Garcia-Romero, Daniel Povey, and Sanjeev Khudanpur. Deep neural network embeddings for text-independent speaker verification. In Interspeech, volume 2017, pages 999–1003, 2017.
[100] David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. X-vectors: Robust dnn embeddings for speaker recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5329–5333. IEEE, 2018.
[101] Rohan Taori, Amog Kamsetty, Brenton Chu, and Nikita Vemuri. Targeted adversarial examples for black box audio systems. In 2019 IEEE Security and Privacy Workshops (SPW), pages 15–20. IEEE, 2019.
[102] Florian Tramer, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, ` Dan Boneh, and Patrick McDaniel. Ensemble adversarial training: Attacks and defenses. In Proc. of ICLR, 2018.
[103] Christophe Veaux, Junichi Yamagishi, Kirsten MacDonald, et al. Superseded-cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit. 2016.
[104] Disong Wang, Liqun Deng, Yu Ting Yeung, Xiao Chen, Xunying Liu, and Helen Meng. Vqmivc: Vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion. arXiv preprint arXiv:2106.10132, 2021.
[105] Qian Wang, Baolin Zheng, Qi Li, Chao Shen, and Zhongjie Ba. Towards query-efficient adversarial attacks against automatic speech recognition systems. IEEE Transactions on Information Forensics and Security, 16:896–908, 2020.
[106] Xiaosen Wang and Kun He. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1924– 1933, 2021.
[107] Emily Wenger, Max Bronckers, Christian Cianfarani, Jenna Cryan, Angela Sha, Haitao Zheng, and Ben Y Zhao. ” hello, it’s me”: Deep learning-based speech synthesis attacks in the real world. In Proc. of ACM CCS, pages 235–251, 2021.
[108] M. Wester and R. Karhila. Speaker similarity evaluation of foreignaccented speech synthesis using HMM-based speaker adaptation. In Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5372–5375, 2011.
[109] Eric Wong, Leslie Rice, and J Zico Kolter. Fast is better than free: Revisiting adversarial training. arXiv preprint arXiv:2001.03994, 2020.
[110] Da-Yi Wu and Hung-yi Lee. One-shot voice conversion by vector quantization. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7734– 7738. IEEE, 2020.
[111] Cihang Xie, Zhishuai Zhang, Yuyin Zhou, Song Bai, Jianyu Wang, Zhou Ren, and Alan L Yuille. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2730– 2739, 2019.
[112] Zhuolin Yang, Bo Li, Pin-Yu Chen, and Dawn Song. Characterizing audio adversarial examples using temporal dependency. arXiv preprint arXiv:1809.10875, 2018.
[113] Zhiyuan Yu, Yuanhaur Chang, Ning Zhang, and Chaowei Xiao. Smack: Semantically meaningful adversarial audio attack. 2023.
[114] Xuejing Yuan, Yuxuan Chen, Yue Zhao, Yunhui Long, Xiaokang Liu, Kai Chen, Shengzhi Zhang, Heqing Huang, XiaoFeng Wang, and Carl A Gunter. Commandersong: A systematic approach for practical adversarial voice recognition. In Proc. of USENIX Security, 2018.
[115] Eiji Yumoto, Wilbur J Gould, and Thomas Baer. Harmonics-to-noise ratio as an index of the degree of hoarseness. The journal of the Acoustical Society of America, 71(6):1544–1550, 1982.
[116] Guoming Zhang, Chen Yan, Xiaoyu Ji, Tianchen Zhang, Taimin Zhang, and Wenyuan Xu. Dolphinattack: Inaudible voice commands. In Proc. of ACM CCS, pages 103–117, 2017.
[117] Ya-Jie Zhang, Shifeng Pan, Lei He, and Zhen-Hua Ling. Learning latent representations for style control and transfer in end-to-end speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6945–6949. IEEE, 2019.
[118] Baolin Zheng, Peipei Jiang, Qian Wang, Qi Li, Chao Shen, Cong Wang, Yunjie Ge, Qingyang Teng, and Shenyi Zhang. Black-box adversarial attacks on commercial speech platforms with minimal information. In Proc. of ACM CCS, 2021.
Annexes
A. Modèles de reconnaissance du locuteur
1) Mécanismes de reconnaissance du locuteur : les modèles de reconnaissance du locuteur [6], [5], [86], [67] sont généralement classés en modèles statistiques, tels que le modèle de mélange gaussien (GMM) basé sur le modèle de fond universel (UBM) [96 ] et l'analyse discriminante linéaire probabiliste (PLDA) à i-vecteurs [38], [85], et les modèles de réseaux neuronaux profonds (DNN) [68], [41]. Il y a trois phases dans la reconnaissance du locuteur.
Dans la phase de formation, un élément clé consiste à extraire les caractéristiques acoustiques des locuteurs, qui sont généralement représentées par les caractéristiques vocales codées de basse dimension (par exemple, les vecteurs i [38] et les vecteurs X [100]). Ensuite, ces caractéristiques peuvent être entraînées par un classificateur (par exemple, PLDA [57]) pour reconnaître différents locuteurs.
2) Pendant la phase d'inscription, pour que le classificateur apprenne le modèle vocal d'un locuteur, celui-ci doit généralement fournir plusieurs échantillons de parole dépendants du texte (par exemple, Siri [3] et Amazon Echo [1]) ou indépendants du texte. système de reconnaissance. En fonction du nombre de locuteurs inscrits, les tâches de reconnaissance du locuteur [29], [118], [113] peuvent être (i) une identification du locuteur (SI) basée sur plusieurs locuteurs ou (ii) une vérification du locuteur basée sur un seul locuteur (SV). ).
3) Dans la phase de reconnaissance, le modèle de reconnaissance du locuteur prédira l'étiquette du locuteur ou produira un résultat de rejet basé sur le seuil de similarité. Plus précisément, le SI peut être divisé en identification fermée (CSI) et identification ouverte (OSI) [39], [29]. Le premier prédit l’étiquette du locuteur avec le score de similarité le plus élevé, et le second n’émet une prédiction que lorsque le score de similarité est supérieur au seuil de similarité ou donne une décision de rejet dans le cas contraire. SV se concentre uniquement sur l’identification d’un locuteur spécifique. Si la similarité dépasse un seuil de similarité prédéterminé, SV renvoie une décision acceptée. A défaut, il rendra une décision de rejet.




B. Comparaison des modèles PT et GT
Construction de modèles PT : il existe plusieurs façons de configurer et de comparer les modèles PT et GT. Nous avons configuré les modèles sur la base de notre scénario d'attaque boîte noire, dans lequel l'attaquant sait que le locuteur cible est formé dans un modèle de reconnaissance de locuteur mais ne connaît pas les autres locuteurs du modèle. Nous construisons d’abord un modèle GT en utilisant des échantillons de parole de plusieurs locuteurs, y compris celui du locuteur cible. Pour construire un modèle PT pour l'attaquant, nous partons de la seule information que l'attaquant est censé connaître (c'est-à-dire un court échantillon de parole du locuteur cible) et nous l'utilisons pour générer différents échantillons de parole de perroquet. Ensuite, nous utilisons ces échantillons de perroquets, ainsi que des échantillons de parole provenant d'un petit ensemble de locuteurs (différents de ceux utilisés dans le modèle GT) dans un ensemble de données open source, pour créer un modèle PT.
Nous utilisons CNN et TDNN pour créer deux modèles GT, appelés respectivement CNN-GT et TDNN-GT. Chaque modèle GT est entraîné avec 6 locuteurs (étiquetés de 1 à 6) de LibriSpeech (90 échantillons de parole pour l'entraînement et 30 échantillons pour les tests pour chaque locuteur). Nous construisons 6 modèles PT basés sur CNN, appelés CNN-PT-i, et 6 modèles PT basés sur TDNN, appelés TDNN-PTi, où i varie de 1 à 6 et indique que le haut-parleur cible de l'attaquant i dans le modèle GT et utilise un seul de ses échantillons de parole pour générer des échantillons de perroquet, qui sont utilisés avec des échantillons de 3 à 8 autres locuteurs sélectionnés au hasard dans VCTK (aucun n'est dans les modèles GT), pour entraîner un modèle PT.
Métriques d'évaluation : Nous visons à comparer les modèles 12 PT avec les modèles 2 GT lors de la reconnaissance du locuteur cible de l'attaquant. Des études existantes [71], [66] ont étudié comment comparer différents modèles d'apprentissage automatique via les résultats de classification. Nous suivons la stratégie commune et validons si les modèles PT ont des performances similaires aux modèles GT via des mesures de classification communes, notamment Recall [37], Precision [45] et F1-Score [84], où le rappel mesure le pourcentage de cible correctement prédite. échantillons de parole sur le total des échantillons cibles réels, la précision mesure la proportion de la parole qui est prédite car l'étiquette cible appartient effectivement au locuteur cible, et F1-Score fournit une mesure équilibrée des performances d'un modèle qui est la moyenne harmonique de la Rappel et précision. Pour tester chaque modèle PT (ciblant le locuteur i) et mesurer les métriques de sortie par rapport aux modèles GT, nous utilisons 30 échantillons de parole de vérité terrain du locuteur i de LibriSpeech et 30 échantillons de chaque autre locuteur de VCTK dans le modèle PT.

Fig. 11 : Comparaison des modèles PT et GT.
Analyse des résultats et discussion : la figure 11 montre les performances de classification des modèles PT et GT. Il ressort de la figure que CNN-GT/TDNN-GT atteint le rappel, la précision et le score F1 les plus élevés, qui vont de 0,97 à 0,98. Nous pouvons également constater que la plupart des modèles PT ont des performances de classification légèrement inférieures mais similaires à celles des modèles GT. Par exemple, CNN-PT-1 a des performances similaires à TDNNGT (Rappel : 0,93 contre 0,98 ; Précision : 0,96 contre 0,98 ; F1-Score 0,95 contre 0,98). Les résultats indiquent qu'un modèle PT, construit uniquement sur un échantillon de parole du locuteur cible, peut toujours reconnaître la plupart des échantillons de parole du locuteur cible, et également rejeter de manière fiable l'étiquetage d'autres locuteurs comme locuteurs cibles en même temps. Le modèle TDNN-PT-4 le moins performant atteint un rappel de 0,82 et une précision de 0,86, ce qui reste acceptable pour reconnaître le locuteur cible. Dans l’ensemble, nous notons que les modèles PT peuvent atteindre des performances de classification similaires à celles des modèles GT. Sur la base des résultats, nous sommes motivés à utiliser un modèle PT pour approximer un modèle GT dans la génération d'AE, et visons à explorer plus en détail si les PT-AE sont efficaces pour être transférés vers un modèle GT boîte noire.
C. Performances des modèles de reconnaissance des locuteurs de lignes numériques
Le tableau IX montre les performances des modèles de reconnaissance du locuteur cible, où la précision indique le pourcentage d'échantillons de parole correctement étiquetés par un modèle dans la tâche CSI ; Le taux de fausses acceptations (FAR) est le pourcentage d'échantillons de parole appartenant à des locuteurs non inscrits mais acceptés en tant que locuteurs inscrits ; Le taux de faux rejets (FRR) est le pourcentage d'échantillons appartenant à un locuteur inscrit mais rejetés ; Le taux d'erreur d'identification en ensemble ouvert (OSIER) est le taux d'erreur égal de OSI-False-Acceptance et OSI-False-Rejection.

TABLEAU IX : Performances des systèmes de reconnaissance du locuteur.

TABLEAU X : Évaluation des différentes distances.
D. Robustesse des PT-AE à distance
Nous visons à évaluer davantage la robustesse de l’attaque PT-AE dans le scénario aérien avec différentes distances entre l’attaquant et la cible. Nous définissons différents niveaux de distance entre l'attaquant (c'est-à-dire le haut-parleur JBL Clip3) et un appareil intelligent, de 0,25 à 4 mètres. Les résultats du tableau X montrent que l'ASR de l'attaque PT-AE évolue avec la distance. En particulier, on constate qu'il n'y a pas de dégradation significative de l'ASR lorsque la distance passe de 0,25 à 0,5 mètres puisque l'ASR diminue légèrement de 60,4% à 58,3% dans le scénario intergenre. Il y a une dégradation évidente de l'ASR lorsque la distance augmente de 2,0 à 4,0 mètres (par exemple, 27,1 % à 14,5 % dans le scénario intergenre). Cela est dû à la dégradation énergétique des PT-AE lorsqu’ils se propagent dans les airs jusqu’à l’appareil cible. Dans l’ensemble, les PT-AE sont assez efficaces dans un rayon de 2,0 mètres étant donné le seuil d’énergie de perturbation de ϵ = 0,08 défini pour toutes les expériences.
E. Discussion sur la défense
Conceptions de défense potentielles : Pour lutter contre les PT-AE, il existe deux principales directions de défense disponibles : (i) le traitement du signal audio et (ii) l'entraînement contradictoire. Le traitement du signal audio a été proposé pour se défendre contre les AE via le sous-échantillonnage [74], [118], la quantification [112] et le filtrage passe-bas [72] pour préserver les principales composantes de fréquence du signal original tout en filtrant les autres composantes. rendre les EI inefficaces. Ces méthodes de traitement du signal peuvent être efficaces lorsqu'il s'agit de traiter le bruit porteur [118], [72], [52], mais ne sont pas facilement utilisées pour filtrer les PT-AE basés sur les sons environnementaux, dont beaucoup ont des gammes de fréquences similaires à celles des humains. discours. L’entraînement contradictoire [51], [78], [20], [25], [97], [102], [109] est l’une des méthodes les plus populaires pour lutter contre les EI. L'idée clé derrière la formation contradictoire est de recycler à plusieurs reprises un modèle cible en utilisant les pires AE pour rendre le modèle plus robuste. Un facteur essentiel dans la formation contradictoire est l’algorithme utilisé pour générer ces AE pour la formation. Par exemple, des travaux récents [118] ont utilisé l’attaque PGD pour générer des AE pour l’entraînement contradictoire, et le modèle devient robuste aux AE basés sur les porteurs de bruit. Un moyen potentiel de défense consiste à générer suffisamment d’AE couvrant une diversité de porteurs et de caractéristiques auditives variables pour l’entraînement. Des conceptions et des évaluations importantes sont nécessaires pour trouver des algorithmes optimaux permettant de générer et de former des AE afin de renforcer un modèle cible.
Source : https://hackernoon.com
Cet article est disponible sur arxiv sous licence CC0 1.0 DEED.